Niveau : Débutant à Confirmé
Durée : de 15 minutes (« piste blanche ») à 1 heure (« piste rouge »).
Prérequis : Connaître l’interface et le fonctionnement des process de Pixinsight.
Objectifs : Prétraiter ses images brutes et obtenir une image empilée finale de qualité en vue du traitement ultérieur.
Vous pourrez retrouver dans les vidéos ci-dessous les principaux aspects abordés dans ce tuto ! Le présent tuto « écrit » demeure toutefois plus complet pour trouver des informations précises…
Introduction
Quelques rappels sur le prétraitement…
Il n’est pas possible dans ce tutoriel de traiter en détails des multiples aspects du prétraitement d’une image astronomique, ce qui prendrait une place considérable. Nous allons juste nous limiter aux informations essentielles qui doivent absolument être connues avant de se lancer dans cette opération, à l’attention des débutants. Je consacrerai peut-être un article plus approfondi dédié à ces questions par la suite…
Une image acquise par une caméra CCD (image « Light« ) contient une multitude de signaux et de bruits différents. En effet, outre le signal lumineux de l’objet photographié, qui est réellement intéressant, elle contient d’autres signaux « parasites » qui contribuent à détériorer le résultat final. Par ailleurs, chacun des signaux (reproductible dans des conditions identiques) est assorti d’un « bruit » (non reproductible même dans des conditions identiques, car aléatoire) qui lui est propre :
- Signal photonique : signal lumineux contenu dans l’image Light, assorti d’un bruit photonique généré par le caractère non-constant du flux lumineux et proportionnel à la racine carrée du signal lumineux (par exemple, pour 100 photons reçus, 10 photons de bruit).
- Signal thermique : signal généré par l’environnement électronique de la caméra, indépendant du signal photonique reçu et fonction de la température du capteur et du temps de pose, assorti d’un bruit thermique non reproductible. Sur une caméra CCD, le signal thermique est diminué par 2 chaque fois par palier d’environ 6,5° : on comprend dès lors bien l’intérêt de disposer d’une caméra refroidie de manière stable.
- Signal d’offset : signal généré par la mesure du courant électrique au sein de chaque photosite du capteur, assorti d’un bruit de lecture indépendant du temps de pose et fonction de la qualité de l’électronique de la caméra (fixe sur une caméra CCD, variant en fonction du gain sur une caméra CMOS).
Outre ces signaux, liés à l’objet photographié et à l’électronique de la caméra, il faut également mentionner deux autres types de défauts importants qu’il convient d’essayer de corriger lors du prétraitement.
- Défauts d’uniformité : défauts liés au fait que la lumière n’est pas reçue de manière uniforme sur l’ensemble du capteur (en raison soit d’un vignettage dans le chemin optique de l’instrument, soit de présence de poussières sur le capteur, les filtres, l’optique de l’instrument…).
- Signaux photoniques parasites : signal parasite généré essentiellement par la pollution lumineuse, la présence de la Lune dans le ciel, airglow, etc.
Signalons que ces deux derniers aspects, contrairement aux précédents, n’ont rien d’obligatoires : on peut imaginer un champ photo parfaitement exempt de tout vignettage, sans aucun signal lumineux parasite sous le meilleur ciel du monde, dont l’utilisateur aurait parfaitement nettoyé la moindre poussière de l’optique… En pratique cependant, nous allons considérer que ces deux phénomènes doivent être systématiquement corrigés, ce qui sera plus fidèle à la réalité de la pratique amateur ! 🙂
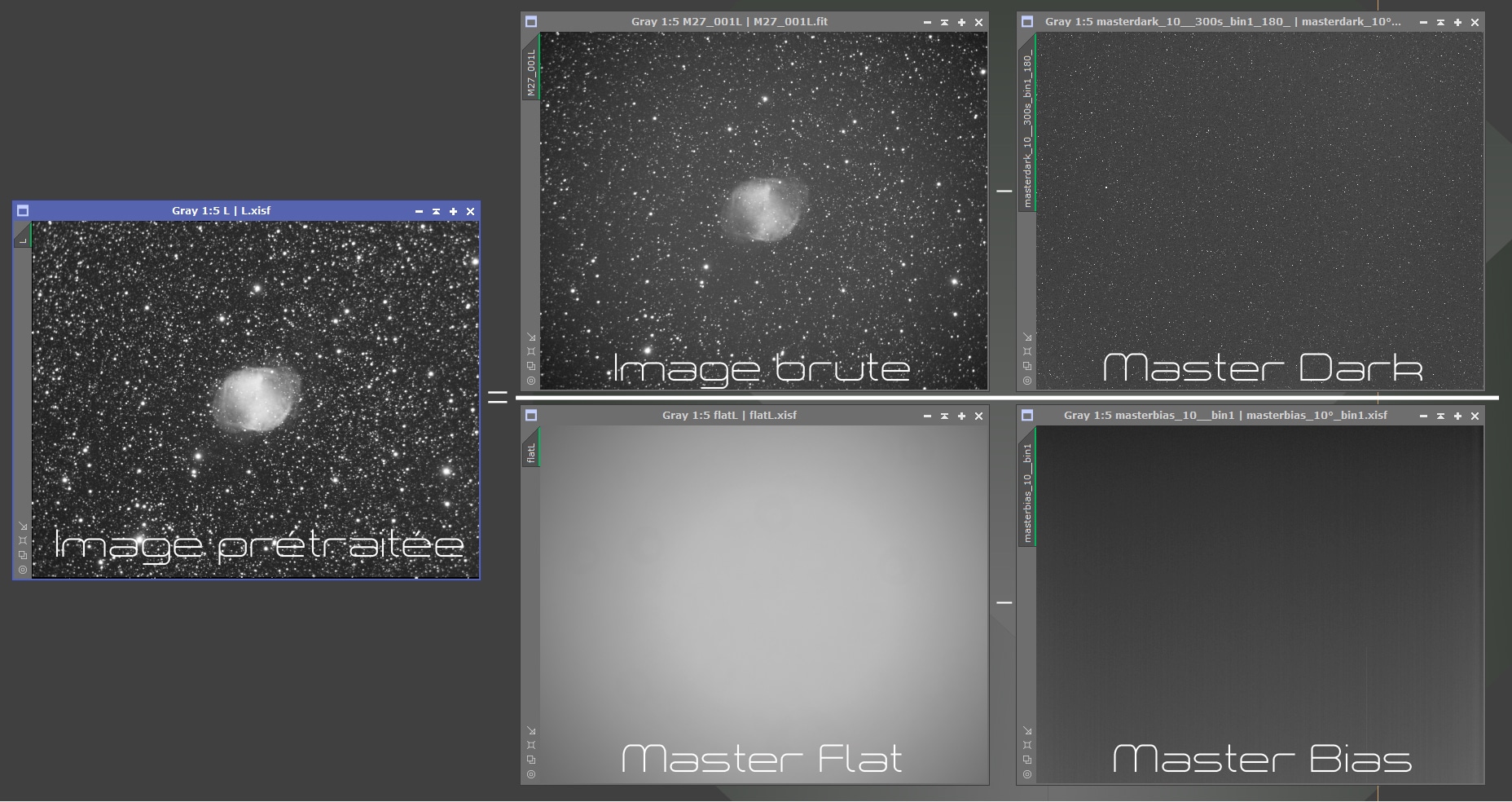
Le but du prétraitement est de supprimer de l’image brute, issue de la caméra, l’ensemble des signaux inutiles et parasites, tout en corrigeant les défauts du capteur ou de la prise de vue, afin de ne conserver que le signal utile.
Pour ce faire, certaines images de calibration doivent être réalisées : les « bias« , les « darks » et les « flats » :
- Les Bias (ou « offset« ) consistent en des images réalisées dans le noir total et avec le plus court temps de pose possible de la caméra : ces images permettent de mesurer le signal de lecture de la caméra et de déduire ce dernier de l’ensemble des images utilisées pour le traitement (Lights, darks, flats).
- Les Darks consistent en des images réalisées dans le noir total et avec le même temps de pose et à la même température que l’image Light : ces images permettent de mesurer le signal thermique de la caméra et de déduire ce dernier de l’image Light (et des flats, si le temps de pose de ces derniers dépasse les quelques secondes…).
- Les Flats consistent en des images de lumière uniforme afin que chaque photosite de la caméra soit soumis à une luminosité strictement identique. Cette image permet ensuite de corriger les défauts d’uniformité du capteur, dus au vignettage ou aux poussières.
Ces images vont être utilisées au cours du prétraitement pour soustraire les différents signaux inutiles de l’image brute. Seuls demeurent les bruits photoniques parasites, qui ne peuvent pas être soustraits par ces images de calibration, et qui donneront lieu à un process spécial plus tard au cours du traitement.
Signalons-le d’emblée, car cela peut sembler contre-intuitif, mais le prétraitement avec ces images de calibration ne permet en aucun cas de supprimer le bruit de l’image : au contraire, le prétraitement ajoute toujours du bruit à l’image de base. En effet, si les signaux parasites peuvent être soustraits, le bruit des images de calibration (non-modélisable) vient s’ajouter au bruit de l’image brute de départ.
Le but du prétraitement est donc de soustraire correctement les signaux parasites, tout en réduisant au maximum l’ajout de bruit par les images de calibration sur chacune des images Light brutes. Signalons que cette démarche débute en réalité dès l’acquisition, en utilisant la technique du « dithering » (léger décalage de quelques pixels entre chaque pose) afin que les défauts des fichiers de calibration ne s’accumulent pas sur les mêmes pixels dans l’image prétraitée.
Il existe une manière très simple de réduire l’incertitude sur la mesure d’un signal : multiplier les mesures ! En l’occurrence, cela revient à multiplier les images. Le rapport signal sur bruit augmente en moyenne comme la racine carrée du nombre de poses.
Par exemple, si le rapport signal sur bruit (S/B) d’une image est de 1 (S/B=1), la combinaison de 9 images aura un rapport S/B=3, la combinaison de 25 images aura un rapport S/B=5, la combinaison de 100 images un S/B=10, etc.
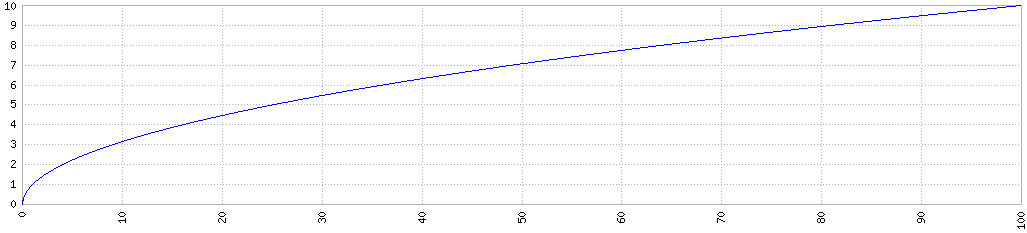
Autrement dit, plus on combine d’images entre elles, plus le rapport S/B s’améliore… mais le gain est de plus en plus faible. Ainsi, pour gagner un facteur 5, il faut combiner 25 images ; mais pour gagner à nouveau un facteur 5, il faut en ajouter encore 75 autres !
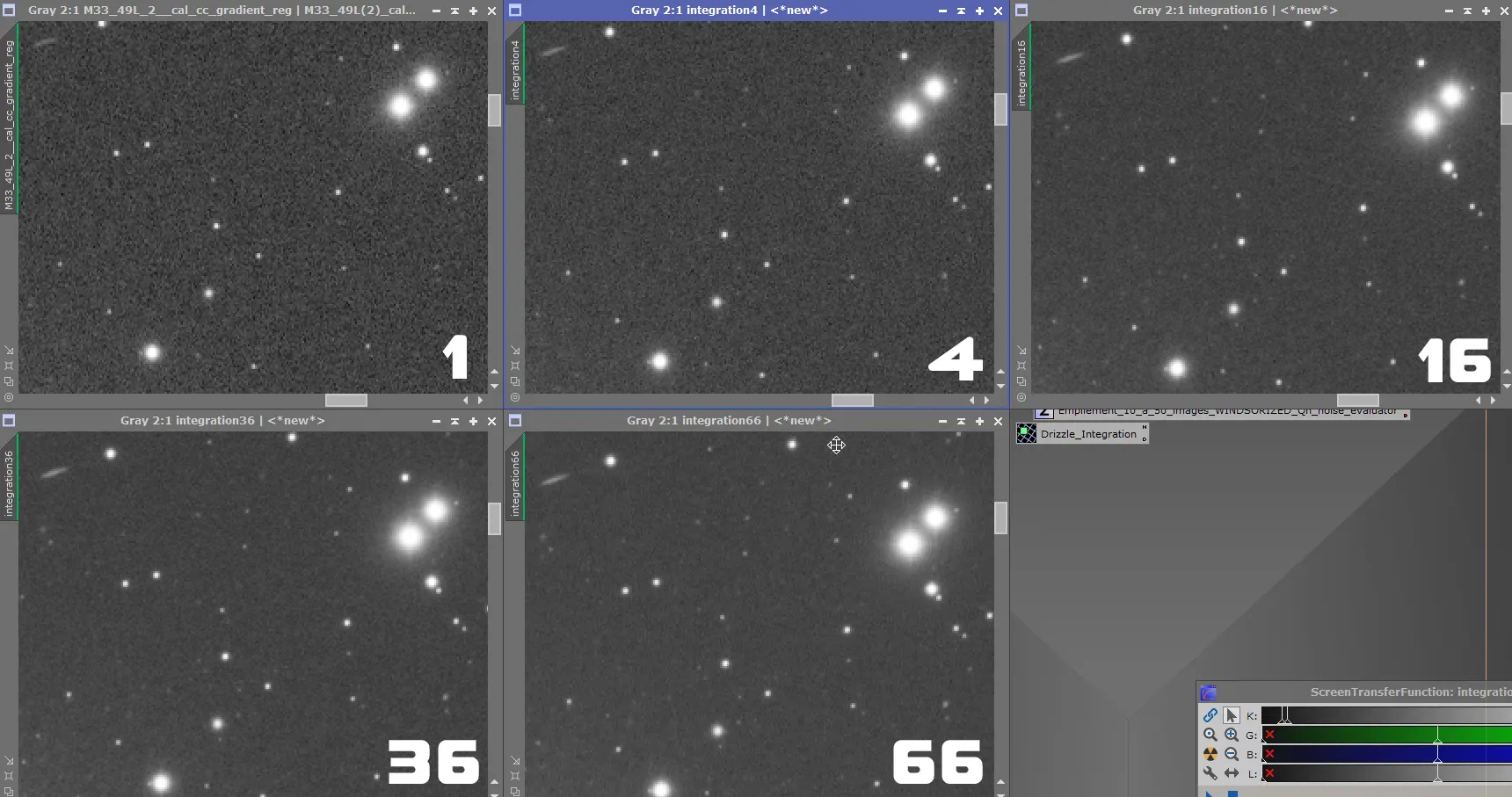
Voici ci-dessous un exemple d’empilement d’un différent nombre d’images brutes, on constate clairement un « lissage » du bruit ainsi qu’une augmentation significative du rapport S/B qui se manifeste dans la détectivité des faibles étoiles :
Ce principe s’applique de la même manière quel que soit le type d’images. En conséquence, il suffit de suivre la même logique pour les images de calibration : en réaliser un nombre suffisant pour augmenter le rapport S/B et ainsi minimiser l’ajout de bruit lors du prétraitement.
La mise en oeuvre de ce principe est surtout importante pour ce qui concerne les images bias et dark puisque, réalisées sans aucun signal lumineux en entrée, le rapport S/B des images unitaires est plus faible que pour les flats, qui eux sont idéalement réalisés avec un flux lumineux maximum situé aux 2/3 de l’histogramme (bruit photonique proportionnel à la racine carrée du flux lumineux, donc ici peu important).
Heureusement, contrairement à l’acquisition des images Light, qui sont limitées par les contraintes de temps, météo, etc., les images de calibration bias et darks sont simples à réaliser, en particulier avec une caméra CCD refroidie. Les images de calibration dark et bias peuvent ainsi être réalisées tranquillement sur une ou plusieurs soirées de mauvaise météo… il suffit juste d’y consacrer un temps suffisant !
Il n’y a pas de nombre « idéal » d’images de calibration à réaliser : ce nombre va dépendre du type de caméra, du refroidissement, du type d’objets photographiés (RGB ou SHO qui va supposer de minimiser au maximum le bruit).
Les bias étant très simples à réaliser et indépendants des temps de pose, on peut se permettre le luxe d’en réaliser un grand nombre (100, voire plus !).
Pour les darks, le temps à consacrer est nettement plus long, car il est nécessaire d’en réaliser une série pour chaque combinaison de temps de pose, de binning et de température… En pratique, il faut en réaliser un nombre significatif mais il est inutile d’en réaliser autant que les bias…
Pour les flats, enfin, le rapport S/B est déjà correct, donc il est possible de se permettre d’en réaliser un nombre limité… ce qui tombe bien puisque ce sont les seules images de calibration qu’il est indispensable de réaliser lors de la prise de vue !
Les images de calibration vont être combinées pour obtenir respectivement un « Master Bias », un « Master Dark » et un « Master Flat ». On peut conseiller le nombre d’images suivant pour réaliser les « Masters », en gardant à l’esprit qu’il n’y a pas de valeur « idéale » :
- Bias : 25 (minimum) / 64 (standard) / 101 (qualitatif) ;
- Darks : 16 (minimum) / 36 (standard) / 64 (qualitatif) ;
- Flats : 9 (minimum) / 16 (standard) / 25 (qualitatif).
A titre personnel, j’utilise les valeurs suivantes : 101 bias (S/B x 10), 64 darks (S/B x 8) et 16 flats (S/B x 4).
Avec l’ensemble de ces images Masters, il va être possible de calibrer chacune des images Light en appliquant la formule suivante :
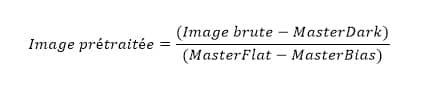
Un exemple plus « visuel » de cette formule :
Comme nous le verrons par la suite, il s’agit du principe « de base » qui peut être légèrement adapté ou optimisé.
Pourquoi procéder à un prétraitement « manuel » ?
Le prétraitement des images brutes est une étape indispensable, mais qui reste souvent considérée par beaucoup d’amateurs comme rébarbative, inintéressante et trop technique… bref, une vraie perte de temps que l’on cherche à accélérer et à automatiser le plus possible afin de passer rapidement à la partie réellement intéressante : le traitement lui-même.
Et pourtant… rien ne saurait être plus faux !
Un grand nombre d’amateurs ont ainsi recours à des logiciels dédiés qui permettent d’obtenir rapidement une image empilée exploitable. Le plus connu d’entre eux est DSS (« DeepSkyStacker« ), mais les utilisateurs de Pixinsight disposent également d’un script similaire, dénommé « Batch Preprocessing ».
La philosophie de ces outils est simple : on rentre l’ensemble des images utiles (light, darks, bias, flat), on configure quelques options et on lance le process avec à la clé, et en quelques minutes, une image empilée qui permet de commencer le traitement.
Pour être honnête, les résultats ainsi obtenus sont souvent très convaincants ! Les options proposées par ces logiciels sont nombreuses et, bien configurées, les images fournies peuvent être très qualitatives. On peut même affirmer que, si l’on considère uniquement le ratio « qualité / temps passé« , ces outils sont imbattables… du moins pour les plus performants d’entre eux !
Par ailleurs, il n’est pas question ici de sous-entendre que les amateurs ayant recours à de tels outils le font par « paresse« , ou sont moins investis dans le traitement de leurs images que les autres… En effet, l’utilisation de ces outils répond à de nombreux besoins pour les photographes de tous niveaux : faciles à utiliser pour les débutants, simples à configurer mais disposant néanmoins de fonctionnalités avancées pour les utilisateurs confirmés, rapides et efficaces pour ceux qui n’ont ni le temps – ni parfois l’envie – de consacrer énormément de temps au traitement de leurs images, gain de temps énorme pour le prétraitement des images couleurs APN ou en cas d’un très grand nombre d’images brutes… les raisons – légitimes – ne manquent pas.
Pourquoi, dès lors, envisager autre chose que ces outils et s’embêter à prétraiter ses images manuellement, avec une succession importante de process différents et en y consacrant un temps beaucoup plus important ?
La raison est simple : les images que vous obtiendrez seront de meilleur qualité ! Et une meilleure qualité des images sorties d’empilement permet ensuite un traitement plus simple et plus poussé des images finales, avec à la clé également de meilleurs résultats.
« Affirmation gratuite », me direz-vous ? Pas vraiment.
A titre personnel, j’ai commencé – comme beaucoup – à prétraiter mes images avec DSS. Mais les premiers essais de prétraitement manuel avec Pixinsight m’ont rapidement convaincu du potentiel bien plus grand des images ainsi obtenues : moins de bruit, un signal plus présent, des étoiles plus fines. C’est notamment ce dernier point – la finesse des étoiles – qui m’a définitivement convaincu de basculer sur Pixinsight y compris pour le prétraitement : c’est à mon sens la principale faiblesse de DSS, sur lequel les étoiles ne ressortent quasiment jamais parfaitement ponctuelles. Je peux même affirmer qu’un rapide coup d’œil (exercé) sur une image permet de déterminer immédiatement si le prétraitement a été réalisé avec DSS, juste en regardant l’aspect des étoiles.
Un exemple ? Voici la comparaison d’une même image empilée avec DSS et avec Pixinsight, avec les mêmes données de calibration et en consacrant la même attention dans le réglage des paramètres pour les 2 versions :



Aujourd’hui, je ne prétraite plus mes images qu’en manuel. Cependant, le but n’est pas de vous convaincre d’abandonner les processus automatisés de prétraitement car, ainsi qu’il a été évoqué ci-dessus, ceux-ci peuvent parfaitement répondre aux besoins et contraintes qui vous sont propres.
Par ailleurs, commencer directement par un prétraitement manuel peut être contre-productif pour les « grands débutants » : d’une part, car le réglage des différentes options doit être compris et maîtrisé à chaque étape, ce qui augmente le risque d’erreurs (et donc de frustration et de temps perdu…) et surtout car si la qualité des brutes sorties d’empilement est meilleure, encore faut-il être capable d’exploiter ensuite ce gain qualitatif lors du traitement ! En effet, les gains obtenus demeurent subtils et un traitement basique ou approximatif ensuite ne permettra pas de les exploiter. Mieux vaut donc rester sur un prétraitement automatisé qui délivrera rapidement et de manière fiable une image propre – à défaut d’être parfaite – et qui permettra de gagner en expérience lors du traitement.
Mais pour tous les autres astrophotographes (de niveau intermédiaire à confirmé), je ne peux que recommander fortement d’essayer, au moins une fois, un prétraitement manuel :
- le paramétrage à chaque étape permet de mieux comprendre les subtilités du prétraitement et d’obtenir des résultats plus fins ;
- de nombreuses fonctionnalités avancées permettent un gain substantiel de qualité, notamment la gestion des gradients sur chaque brute unitaire préalablement à l’empilement, la création d’un superbias, une sélection et une pondération optimisée des meilleures brutes, etc.
- la génération d’une image en mode « drizzle » est plus performante avec Pixinsight qu’avec DSS.
Si toutefois vous hésitez à vous « lancer » avec Pixinsight, une solution médiane est possible : conservez le « BatchPreprocessing » pour la réalisation des images de calibration (bias, darks, flats) mais réalisez le prétraitement de vos images Light et l’empilement en mode manuel… et regardez la différence ! 🙂
La méthode proposée dans ce tutoriel : une approche par niveaux
Le processus de prétraitement manuel sous Pixinsight peut prendre différentes formes, plus ou moins avancées, selon votre niveau, vos attentes et le temps que vous souhaitez y consacrer. La qualité des images brutes a également son importance : s’il est légitime de chercher à optimiser au maximum le prétraitement de brutes d’excellentes qualité, le cas échéant en y consacrant un temps important, un prétraitement plus simple et rapide pourra suffire pour des brutes moins bonnes…
Ainsi, le présent tutoriel se présente sous la forme d’un « parcours de ski », ouvert à tous les niveaux mais avec des pistes recommandées selon votre expérience :
Rappelez-vous : les process de la « piste blanche » sont indispensables et ne peuvent pas être sautés ! Pour les process complémentaires, vous êtes libres de vous aventurer sur tout ou partie des pistes bleue et rouge… mais attention, en cas de « hors-piste », je ne saurais être tenu pour responsable d’un quelconque accident de parcours ! 🙂
Étapes de traitement
- Soustraction du signal d’offset par les Bias
- Soustraction du signal thermique par les Darks
- Correction des défauts d’uniformité par les Flats
- Calibration des images Light brutes
- Correction cosmétique
- Retrait de gradients
- Sélection et pondération des images Light
- Alignement des images Light
- Local Normalization
- Empilement des images Light
- Génération d’une image Light Drizzle
1. Soustraction du signal d’offset par les Bias
Dans la mesure où le signal d’offset est présent sur chacune des images issues de la caméra (light, dark, flat), il est nécessaire de débuter par la création d’une image modélisant au mieux ce signal.
C’est le but des images bias, qui vont être combinées pour générer un MasterBias optimisant le rapport S/B.
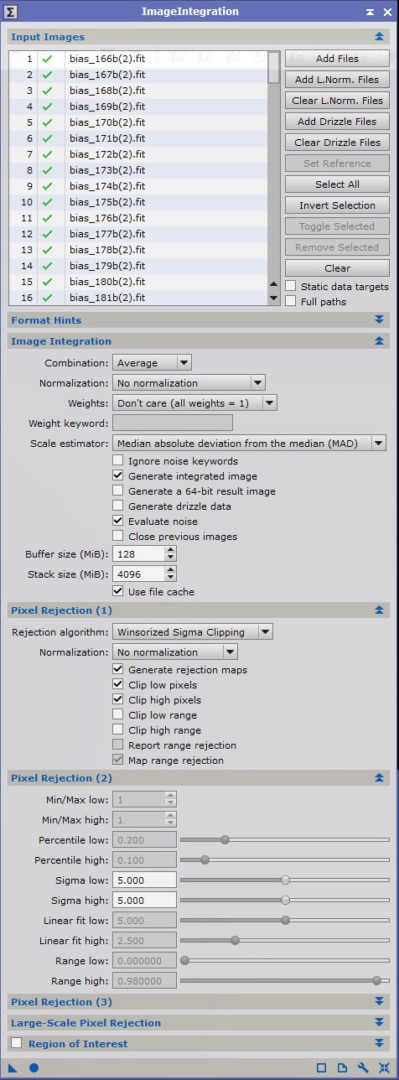
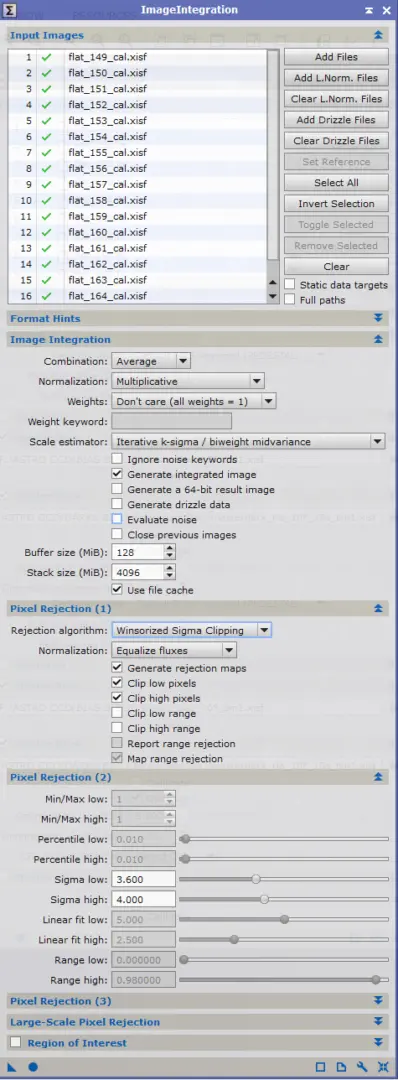
Nous allons pour ce faire utiliser le process ImageIntegration, paramétré avec les options telles que figurant dans l’image d’exemple ci-contre (les volets non-ouverts ne contiennent aucune option activée).
La première étape est d’ajouter dans « Input Images » l’ensemble des images bias réalisées. Comme nous l’avons expliqué précédemment, un grand nombre est recommandé.
Il faut veiller à conserver le mode de combinaison « Average » (moyenne), plus efficace que la médiane pour optimiser le rapport S/B (racine carrée du nombre d’images pour la moyenne, contre 0,8 x racine carrée du nombre d’images pour la médiane).
L’option « Generate integrated image » ; mais « Evaluate noise » n’est pas indispensable ; ne la conservez que si vous avez besoin de la mesure de bruit sur chacune des images brutes de bias utilisées.
Les modes « No normalization » et « Don’t care (all weights = 1) » doivent être sélectionnés. En effet, pour ces images, aucune optimisation ou pondération n’est justifiée à ce stade car elle fausserait les valeurs réelles des bias (notamment le pedestal).
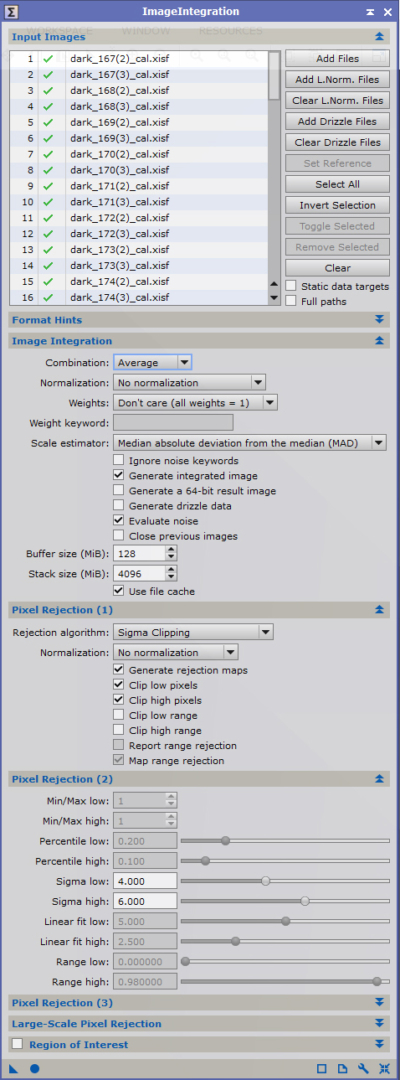
L’algorithme de réjection de pixels doit être configuré en fonction du nombre n d’images combinées :
- n < 10 : Average sigma clipping ;
- 10 < n < 25 : Winsorized sigma clipping ;
- n > 25 : Linear fit clipping.
Dans tous les cas, cochez « Clip low pixels » et « Clip high pixels » mais désactivez « Clip low/high range » : la réjection ne doit porter que sur les pixels et non sur des plages de valeurs. Cochez également « Generate rejection maps ».
Les valeurs de ces réjections sont à préciser dans la fenêtre suivante. A ce stade, l’idée est d’effectuer le moins de réjection possible afin d’avoir une représentation la plus fidèle possible du signal d’offset.
Il convient donc de retenir des valeurs de sigma assez élevées pour que soient pris en compte la quasi-totalité des valeurs, avec seulement la réjection des valeurs qui s’écartent très significativement de l’écart-type. Une valeur de 5 ou 6 sigma est à retenir.
L’image ainsi obtenue constitue le fichier « MasterBias ».
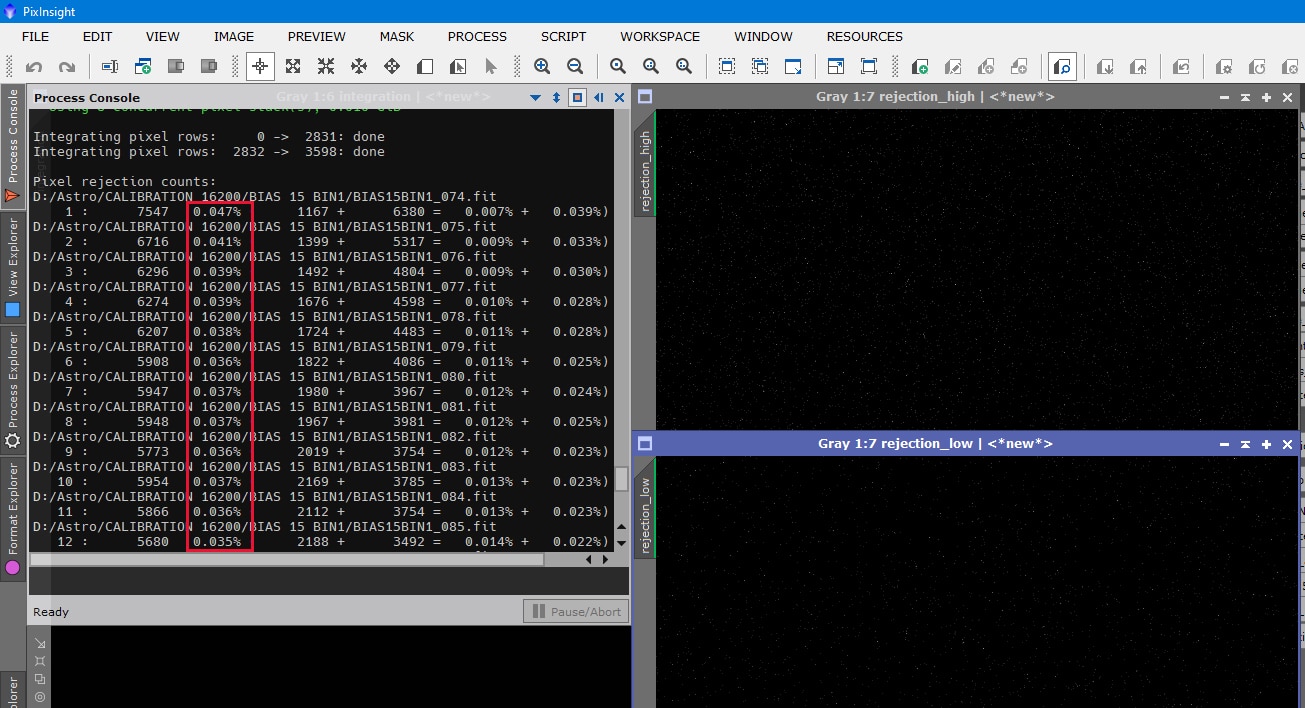
Si vous avez bien laissé cochée l’option « Generate rejection maps », Pixinsight génère également, en plus de l’image d’intégration, 2 autres images montrant les pixels de valeur trop basse ou trop haute rejetés pour cette raison sur la base des paramètres de sigma prédéfinis.
Il est important, pour confirmer la pertinence de l’image MasterBias obtenue, de vérifier ces deux images de réjection avec la fonction STF. Le nombre de pixels rejetés doit rester très marginal (ces pourcentages sont visibles dans le « Process Console » affichés en fin de traitement pour chacune des images). Si un trop grand nombre de pixels sont rejetés (soit en « low », soit en « high »), il convient de procéder à une nouvelle intégration en modifiant les paramètres Sigma low et/ou Sigma high dans « Pixel Rejection (2) ».
Une fois cette vérification procédée, sauvegardez l’image issue de l’intégration en tant que MasterBias. Utilisez le format fits ou, mieux encore, le format xisf, format dédié de Pixinsight, beaucoup plus puissant et rapide à utiliser avec ce logiciel (notez également que ce format xisf est désormais utilisé par défaut dans les process d’intégration et de calibration).
N’oubliez pas qu’un MasterBias doit être réalisé pour chaque combinaison de température et de binning. Aussi, il est recommandé pour s’y retrouver plus tard de renseigner ces informations essentielles directement dans le nom du fichier sauvegardé, par exemple « MasterBias_10°_bin1 ».
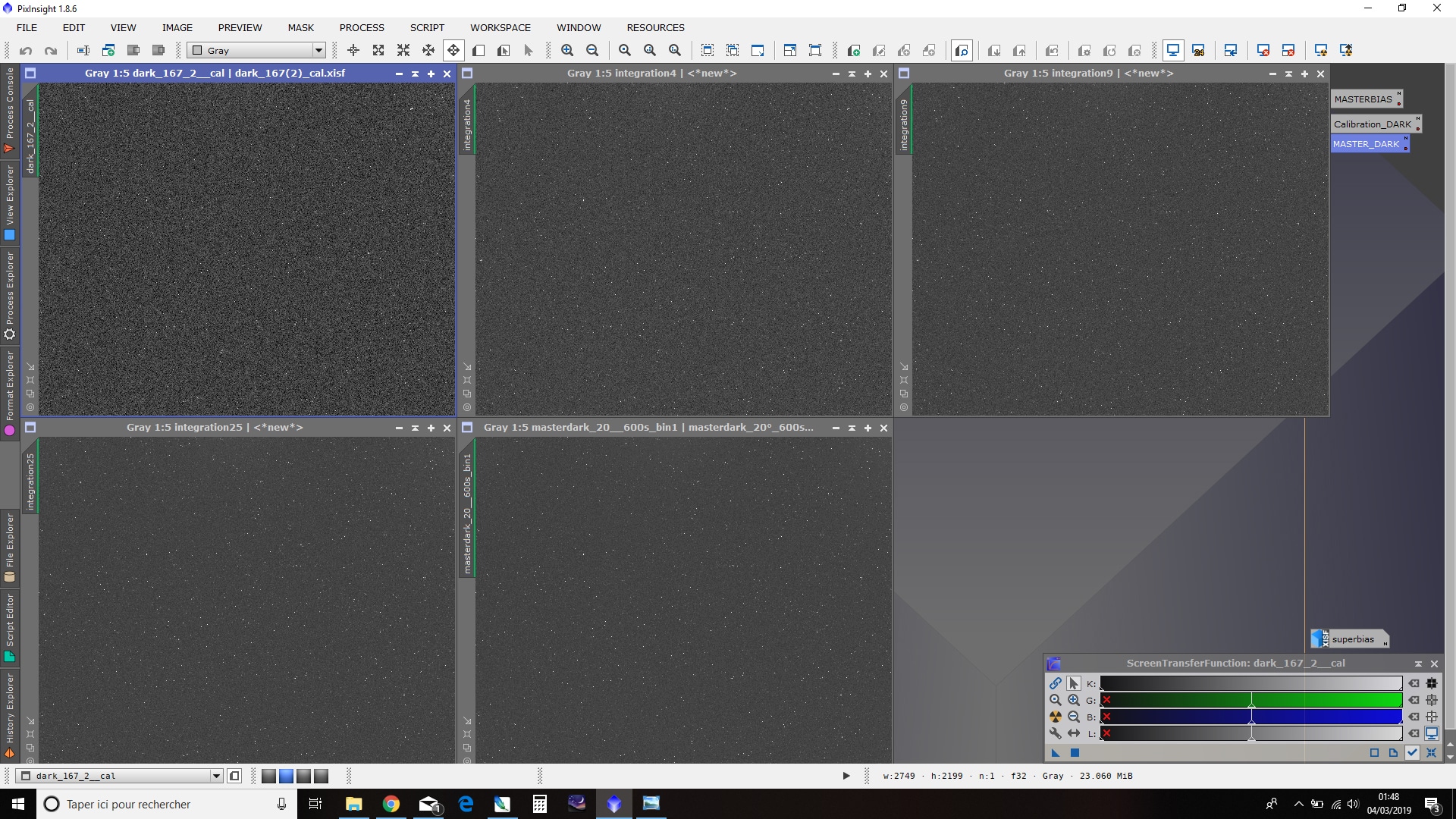
Comme rappelé précédemment, le but de créer un MasterBias est d’augmenter le rapport S/B du signal d’offset, et donc de limiter le bruit ajouté lors du prétraitement. Il est donc primordial de combiner un nombre suffisant d’images bias.
Ci-dessous un comparatif du résultat obtenu pour le MasterBias en combinant 1, 4, 10, 25 et 100 bias, visualisé en mode STF avec comme référence le STF de l’image 100bias :
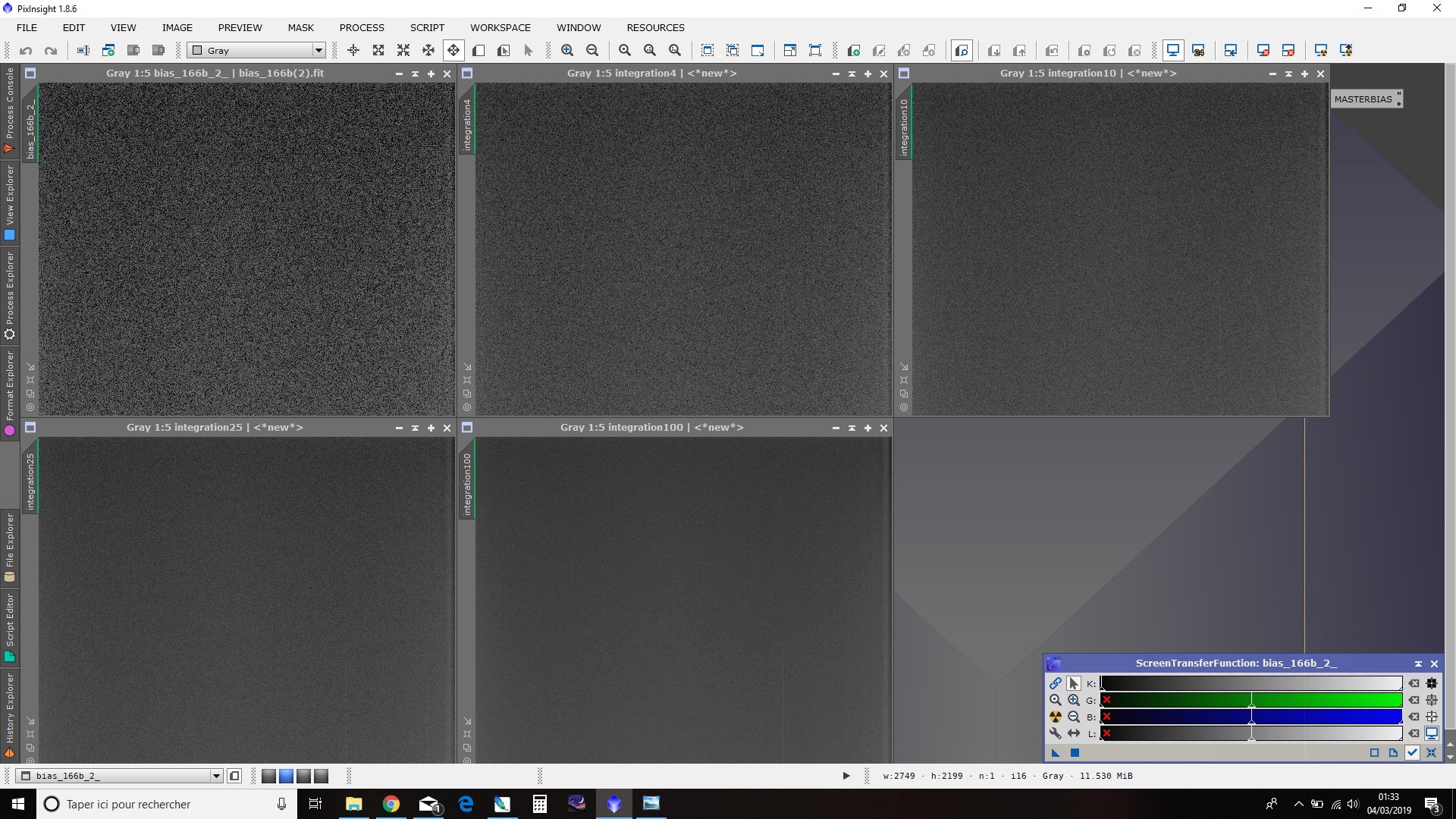
L’amélioration du rapport S/B avec le nombre d’images combinées est flagrante : il est primordial de réaliser le MasterBias avec le plus d’images possibles !
Créer un MasterBias avec un grand nombre d’images permet déjà, comme on vient de le voir, de réduire fortement le bruit d’offset… mais il est possible d’aller encore plus loin en créant un « SuperBias ».
Ce process permet, à partir d’un MasterBias, d’extrapoler la combinaison de plusieurs dizaines de fois le nombre d’images réellement utilisées pour créer le MasterBias ! Si vous avez combiné 20 images, le process Superbias vous donnera un résultat équivalent à une combinaison de 400 bias ; avec 100 bias, de plusieurs milliers !
Ne nous privons donc pas de l’utiliser, d’autant plus qu’il est très simple. Par ailleurs, en cas de très faibles valeurs sur les darks, la soustraction d’un MasterBias peut entraîner des valeurs à 0 sur certains pixels et générer des erreurs ; un SuperBias permet de limiter ce problème.
Il suffit d’appliquer le process « SuperBias » sur le MasterBias, en conservant les paramètres par défaut. Si vous avez utilisé un grand nombre de bias pour créer le MasterBias, ce dernier est déjà très « propre », aussi vous pouvez essayer de diminuer la valeur de « Multiscale layers » à 6. Sinon, conserver la valeur 7 par défaut afin de prendre en compte des structures de bruit plus importantes.
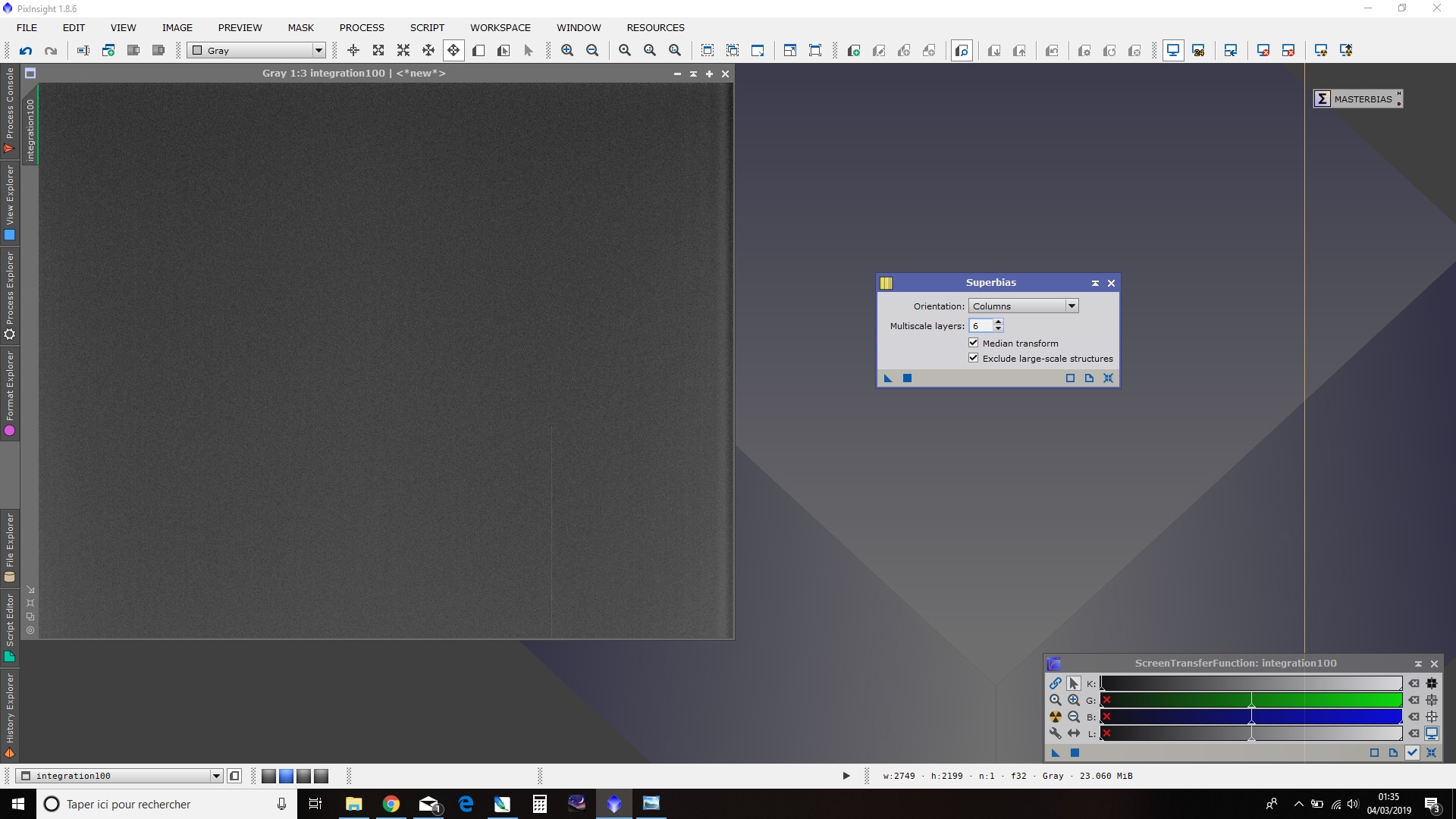
Après traitement, une nouvelle image est créée : il s’agit du Superbias. Examinez-là avec la fonction STF et vous constaterez que l’ensemble du bruit résiduel a totalement disparu : seul demeure visible le signal d’offset avec un dégradé caractéristique dont l’intensité est maximale à proximité de l’amplificateur de sortie de la caméra.
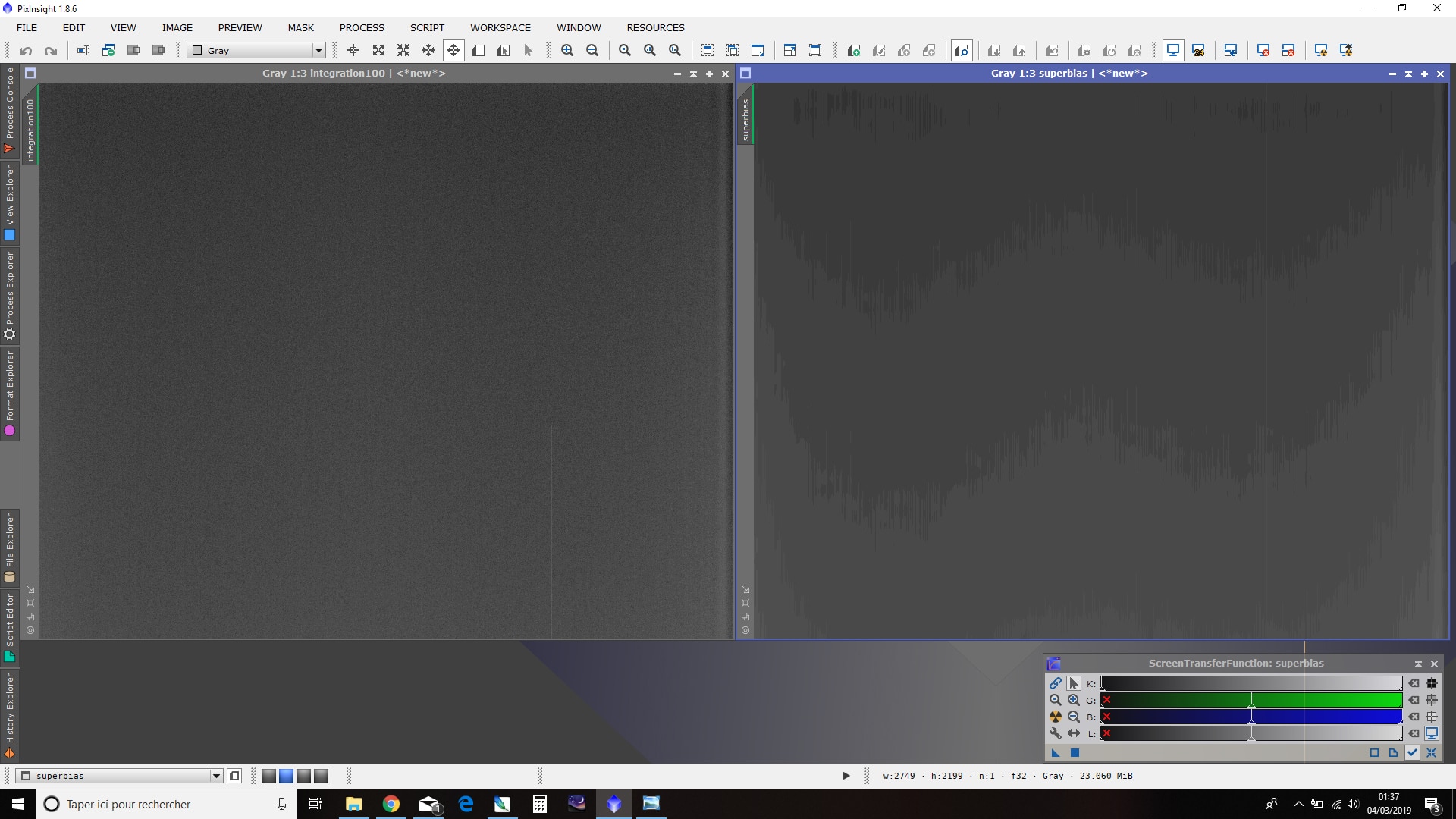
Sauvegardez ce SuperBias de la même manière que le MasterBias.
Le SuperBias se substituera au MasterBias dans la suite du prétraitement.
2. Soustraction du signal thermique par les Darks
De la même manière que nous l’avons fait pour les bias, nous allons désormais pouvoir combiner une multitude d’images darks pour réaliser un MasterDark qui nous permettra de déduire le signal thermique en ajoutant un minimum de bruit à l’image Light.
Mais les darks contenant eux-même le signal d’offset, une étape préalable va consister à soustraire de chaque image darks le MasterBias (ou Superbias si vous avez retenue cette option).
Calibration des darks avec MasterBias (ou SuperBias)
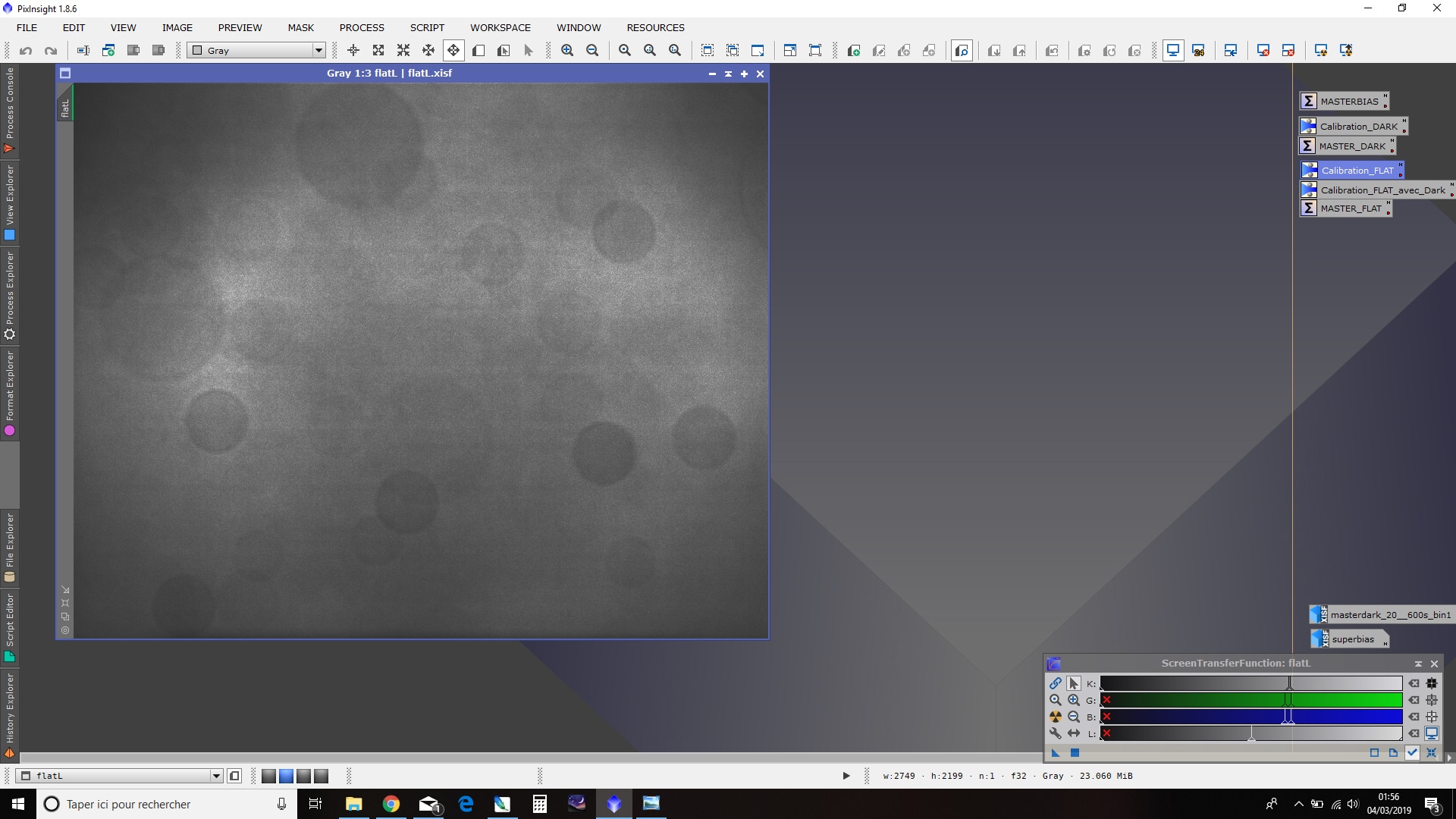
Pour ce faire, nous utilisons le process ImageCalibration.
Dans « Target Frames », ajoutez l’ensemble des images unitaires de darks.
Un point important est de vérifier l’absence de « Pedestral » ; celui-ci doit être maintenu à 0. Pour faire simple, cette option peut être utilisée en certaines occasions en guise « d’offset sans bruit » ou pour ajouter une valeur définie à tous les pixels de l’image ; mais cela est inutile ici.
Renseignez le fichier MasterBias (ou SuperBias) créé préalablement ; tout en laissant décochée l’option « Calibrate ». Il est inutile d’envisager une quelconque calibration dès lors que les darks et les bias sont réalisés à des températures identiques.
Par défaut, les fichiers darks calibrés seront enregistrés dans le même répertoire que les fichiers darks. Modifiez si vous le souhaitez la destination des fichiers ainsi que leur postfix (« _cal » par défaut) dans « Output Files ».
Les autres options doivent être maintenues déactivées.

Création du MasterDark
Une fois cette calibration effectuée, le signal d’offset a été soustrait des fichiers darks unitaires. Il est donc possible de les combiner afin de générer un MasterDark reflétant fidèlement le seul signal thermique avec un bruit réduit.
Pour ce faire, nous utilisons à nouveau le process ImageIntegration.
Dans « Input Images », renseignez l’ensemble des images darks qui viennent d’être calibrées.
Ici encore, le mode de combinaison par moyenne (« Average ») est plus adapté que la méthode par médiane.
Aucune normalisation ou pondération n’est là non plus nécessaire.
Veillez bien à ce que l’option « Generate integrated image » soit cochée. Vous pouvez décocher l’option « Evaluate Noise » si vous n’êtes pas intéressé par la mesure du bruit de chacune des images darks… et si vous souhaitez accélérer fortement la rapidité du processus !
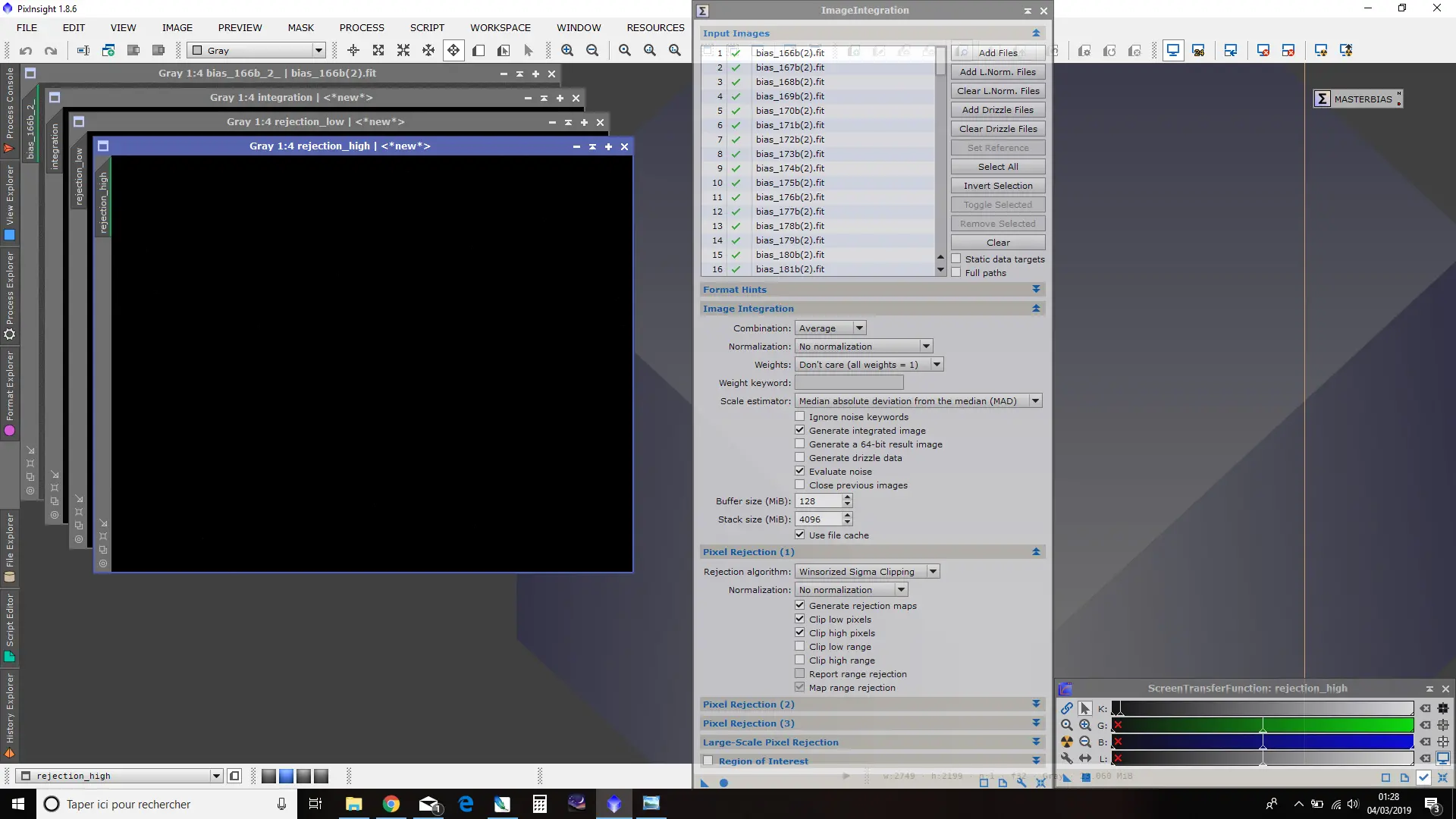
L’algorithme de réjection de pixels doit être configuré en fonction du nombre n d’images combinées :
- n < 10 : Average sigma clipping ;
- 10 < n < 25 : Winsorized sigma clipping ;
- n > 25 : Linear fit clipping.
Comme pour les bias, Activez les options « Clip low/high pixels » mais décochez « Clip low/high range ». Activez également l’option « Generate rejection maps » afin de pouvoir apprécier le résultat des réglages de l’algorithme de réjection après la combinaison des images.
Enfin, réglez la valeur des sigma, low et high, à des valeurs suffisamment hautes pour autoriser les réjections des seules valeurs marginales. A défaut, le MasterDark risque de ne pas corriger efficacement les pixels « morts » et/ou « chauds ».
Une valeur de 5 ou 6 sigma est à retenir ; et il est possible d’attribuer des valeurs distinctes aux sigma low et high (par exemple 4 et 6).
Lancez le process et vérifiez sur les images de réjection low et high qu’un nombre limité de pixels sont présents.
Si de trop nombreux pixels sont présents, affinez les réglages de sigma à la hausse (pour diminuer le nombre de pixels rejetés) ou à la baisse (pour augmenter le nombre de pixels rejetés).
Affinez séparément les valeurs low et high si besoin.
L’image obtenue constitue le MasterDark, qui sera utilisé par la suite pour la calibration des images Light brutes. Sauvegardez-le de la même manière que pour le MasterBias.
Ce MasterDark va permettre de déduire le signal thermique des images Light brutes. Combinez-en le plus possible afin de réduire le bruit au maximum.
A titre d’exemple, voici une comparaison de MasterDark constitué de 1, 4, 9, 25 et 64 darks unitaires : le résultat est sans appel !
En complément : réalisation de MasterDark-Flat
Attention, si les images Lights à prétraiter ont été réalisées avec des filtres narrowband (Ha, OIII, SII…), il est possible que les flats aient nécessité un temps de pose plus long que pour les classiques images L ou RGB. Si le temps de pose des flats unitaires est supérieur à 10 secondes, il devient nécessaire de réaliser un MasterDark-Flat avec des darks réalisés avec un temps de pose identique au temps de pose des flats, à des conditions de binning et de température identiques.
Dans ce cas, réalisez le MasterFlat-Dark de la même manière que celle décrite à la présente section ; celui-ci nous sera nécessaire dans l’étape suivante de calibration.
Passons désormais à la dernière étape de préparation des images de calibration.
3. Correction des défauts d’uniformité par les Flats
Dernière étape de création des fichiers de calibration avec les flats, qui vont permettre de corriger les défauts d’uniformité de la plage lumineuse des images Lights.
De la même manière que pour les bias et les darks, nous allons créer un MasterFlat en combinant les images flats unitaires.
Calibration préalable des flats
Une étape préalable est là encore la calibration des flats unitaires avec le process ImageCalibration.
Deux cas de figure sont possibles :
- la calibration implique seulement la soustraction du signal d’offset (cas le plus courant notamment pour les flats L/R/G/B) ;
- la calibration implique la soustraction du signal d’offset et du signal thermique (avec un MasterDark-Flat pour les flats S/H/O).
Calibration standard avec le seul MasterBias (ou SuperBias)
La procédure à suivre est similaire à celle utilisée précédemment, avec pour débuter une soustraction du signal d’offset de chacune des images flats unitaires.
Lancez le process ImageCalibration.
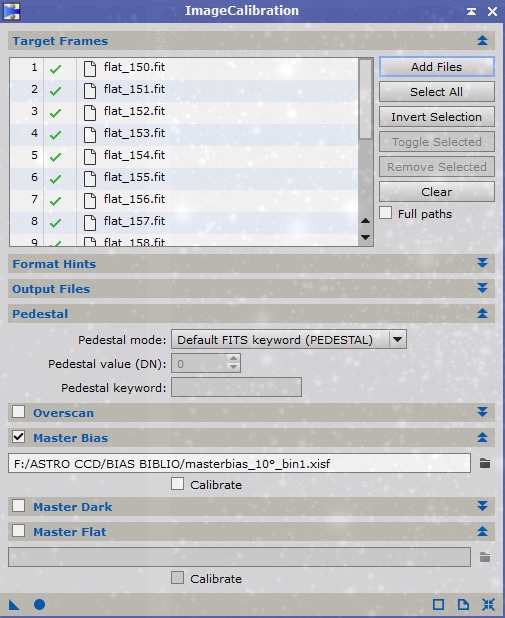
Ajoutez l’ensemble de vos fichiers flats bruts dans « Target Frames », et indiquez le MasterBias (ou le cas échéant le SuperBias) en cochant l’option « Master Bias ».
Aucun « Pedestal » ou calibration n’est nécessaire dans ce cas de figure.
Le cas échéant, modifiez ici les « postfix » des fichiers calibrés (par défaut « _cal ») ainsi que le répertoire de destination (par défaut le même que les images faisant l’objet de la calibration).
Lancez le process et poursuivez directement par l’étape d’empilement des flats calibrés ci-après.
Calibration avec un MasterBias et un MasterDark-Flat
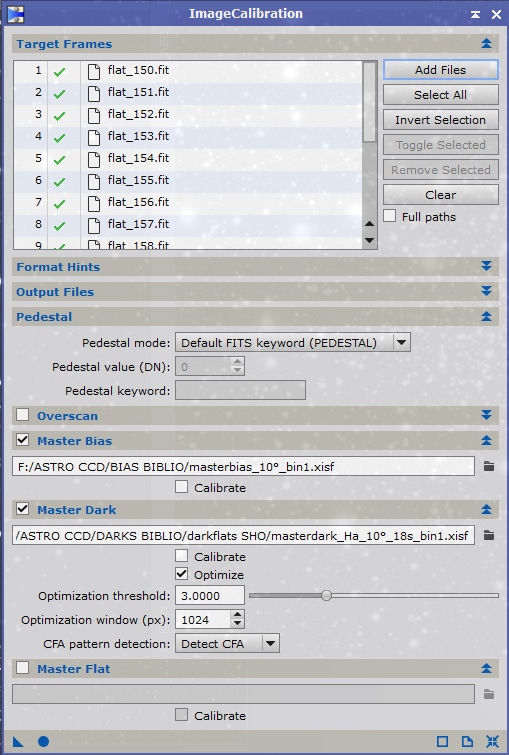
Suivez la même procédure que celle indiquée ci-dessus dans le cas standard pour indiquer le MasterBias (ou SuperBias) à utiliser pour la calibration.
Dans le cas des flats narrowband justifiant la réalisation d’un MasterDark-Flat, il est nécessaire également de soustraire des flats le signal thermique, et donc d’indiquer également le MasterDark-Flat à utiliser, comme dans l’exemple ci-contre.
Si vous utilisez un MasterDark-Flat dont le temps de pose est exactement identique à celui des flats, vous pouvez décocher la case « Optimize » : cette optimisation n’est nécessaire que si votre MasterDark-Flat et les flats n’ont pas rigoureusement le même temps de pose.
Par exemple, avec des flats réalisés avec 20 secondes de pose et un MasterDark-Flat réalisé avec 18 secondes de pose (comme dans l’exemple présenté ici), il est préférable de laisser activée cette « optimisation » du MasterDark-Flat. Les temps de pose sont très proches et l’optimisation donnera de très bons résultats pour éviter toute sous-correction du MasterDark utilisé.
Faites de même si vous ne disposez pas d’un MasterDark-Flat proche, mais uniquement d’un MasterDark classique.
Choisissez dans ce cas le MasterDark disposant de la même combinaison binning/température que celui des images flats, et avec le temps de pose le plus proche de ces dernières.
Si vous utilisez un MasterDark trop éloigné en temps de pose de celui des flats (par exemple un MasterDark de 900s pour des flats de 10s) ou que vos flats sont d’un temps de pose trop court (2 ou 3 secondes), il est très probable que le résultat ne soit pas correct.
En effet, bien que le signal thermique augmente de manière linéaire avec le temps de pose et qu’il soit donc théoriquement possible de déduire une valeur pertinente avec des temps de pose différents, l’optimisation est efficace en pratique jusqu’à un certain point : si les deux valeurs sont trop décorrelées, Pixinsight ne sera pas capable de parvenir à un ajustement fiable et indiquera le message « No correlation…« .
Dans ce cas, il est recommandé de ne pas utiliser de MasterDark plutôt que de réaliser une optimisation hasardeuse…
Création du MasterFlat
Une fois cette calibration réalisée, nous pouvons procéder à l’empilement des images flats calibrées, toujours avec le process ImageIntegration.
Lancez le process ImageIntegration et ajoutez dans « Input Images » l’ensemble des flats précédemment calibrés.
Ici encore, nous conservons un empilement par méthode moyenne « Average » et non par médiane. Cochez « Generate integrated image » (et éventuellement « Noise evaluation » si vous êtes intéressés par les résultats de mesure du bruit à ce stade).
Flats réalisés avec un écran à flats
Si vous effectuez vos flats avec une source lumineuse homogène ou parfaitement uniforme (comme un écran à flats), l’algorithme de réjection par défaut pourra être « Winsorized Sigma Clipping » qui donnera de très bons résultats dans la majorité des cas de figure. Cochez les options comme indiquées dans l’exemple ci-contre.
Les sigmas low et high doivent ensuite être précisés.
Contrairement aux bias et aux darks, le signal d’entrée des flats est très lumineux. Aussi, il est possible d’abaisser les seuils pour exclure davantage de valeurs déviantes : ce sont les défauts à grande échelle qui nous intéressent ici et non les défauts des pixels pris séparément.
Des valeurs comprises entre 3 et 4 donnent de bons résultats en pratique.
Flats réalisés sur le ciel
Si en revanche vous réalisez vos flats directement sur le ciel, il faut prévenir dans la création du MasterFlat l’intégration d’étoiles.
Dans ce cas, privilégiez l’algorithme de réjection « Percentile Clipping » en mode « Equalize Flux », tout en conservant les mêmes options que celles cochées ci-contre.
Il vous faudra ensuite jouer sur les valeurs de « Percentile low / high » dans la fenêtre « Pixel Rejection (2) » en indiquant des valeurs suffisamment basses pour prévenir la prise en compte des étoiles, par exemple en réglant les deux valeurs sur 0,010.
Lancez le process et inspectez les images de réjection low et high afin d’en vérifier la pertinence. Si vos flats ont été réalisés sur le ciel, les étoiles doivent bien avoir été exclues.
Vérifiez ensuite votre MasterFlat, en utilisant la fonction STF afin de renforcer les contrastes et d’apprécier au mieux le résultat.
Dans tous les cas, les poussières doivent bien demeurer visibles sur le MasterFlat final.
Maintenant que nous avons créé toutes les images de calibration nécessaires, nous pouvons passer à la calibration des images Light brutes.
4. Calibration des images Light brutes
A ce stade, nous possédons désormais toutes images nécessaires à la calibration correcte de nos images Light brutes : le MasterBias (ou SuperBias), le MasterDark et le MasterFlat.
Pour rappel, la calibration de chaque image Light brute va consister à appliquer le traitement suivant :
Bien sûr, Pixinsight va se charger d’effectuer cette opération automatiquement et très efficacement.
Lancez le process « ImageCalibration » et ajoutez l’ensemble de vos fichiers Lights bruts dans « Target Frames ».
Modifiez le cas échéant le postfix des fichiers calibrés (par défaut « _cal ») ainsi que le dossier de destination.
Veillez cette fois à ce que l’option « Evaluate Noise » soit bien cochée ! La mesure du bruit de chaque Light prétraitée nous sera utile par la suite pour déterminer la meilleure Light brute et éventuellement appliquer des coefficients de pondération lors du stacking (empilement) des images.
Indiquez dans les fichiers MasterBias (ou SuperBias), MasterDark et MasterFlat à utiliser pour réaliser la calibration.
Si vous avez suivi ce tutoriel sans vous écarter des réglages recommandés, vous pouvez décocher les options « calibrate » pour l’ensemble des images de calibration.
Si vous avez un doute quand à la fiabilité de la régulation thermique de votre caméra (légères fluctuations au cours des temps de pose, de l’ordre de +/- 1°, vous pouvez cochez l’option « optimize » pour le seul MasterDark, afin de compenser ces petites imprécisions, qui affectent les images Light et darks. Si les fluctuations de température sont inférieures et non-significatives, mieux vaut décocher cette option.
En réalité, cette opération cruciale ne pose pas de difficulté particulière, sous réserve d’avoir bien réalisé les images de calibration au préalable !
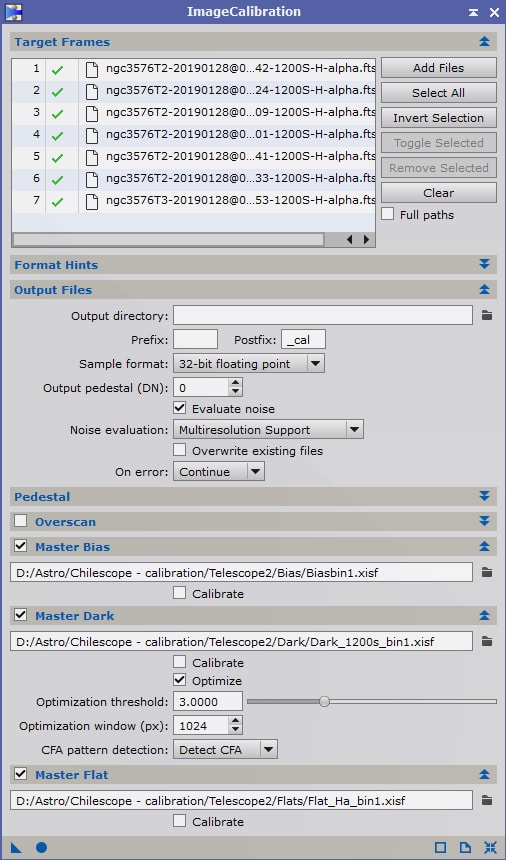
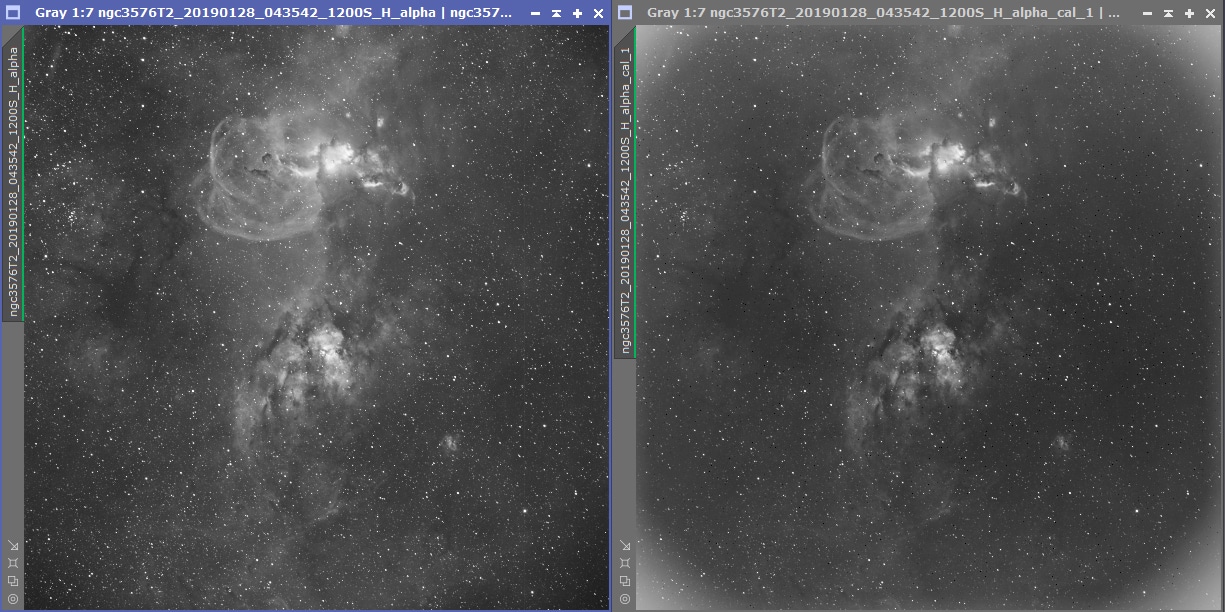
Lancez le process et, avant d’aller plus loin, prenez quelques minutes pour vérifier la qualité des images Light prétraitées obtenues. Ouvrez quelques-unes (ou toutes…) des images brutes de départ et leurs images prétraitées afin de vérifiez qu’il n’y a aucun problème qui « saute aux yeux ».
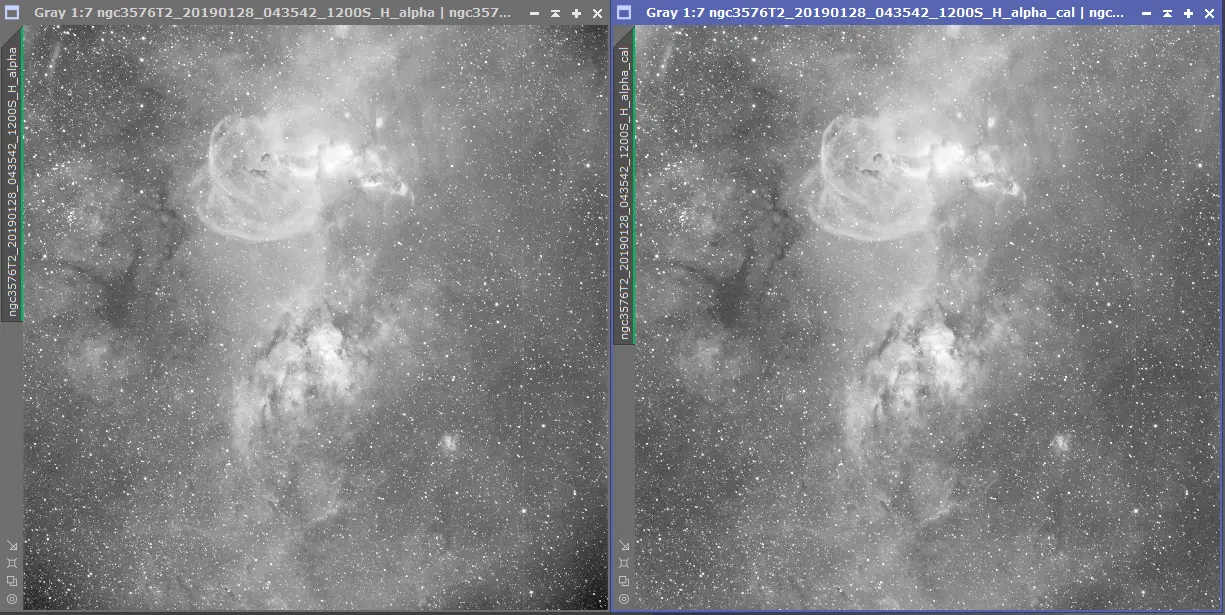
Sur cet exemple, on constate que les flats ont bien rempli leur rôle.
Si les soucis liés aux darks ou aux bias peuvent être assez difficiles à déceler, ceux liés aux flats sont en revanche très bien visibles. La sous-correction ou à la sur-correction des flats notamment, est très simple à évaluer : poussières qui deviennent plus lumineuses que le fond de ciel, coins de l’image trop sombres, etc.
Dans la très grande majorité des cas, ces soucis sont dus à une mauvaise configuration des options de « calibration » ou « d’optimisation » lors de la création des images Masters. Vérifiez que vous n’avez pas coché ou décoché par erreur l’une de ces options lors des étapes précédentes du prétraitement.
La seule différence avec l’exemple précédent est le cochage de l’option « optimisation » du MasterFlat.
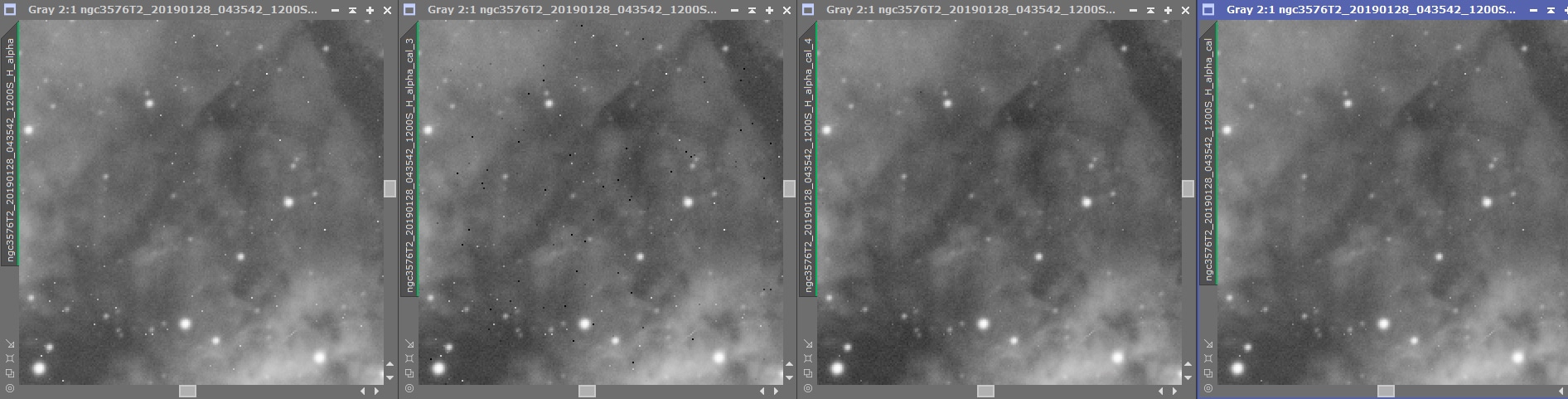
Entre les deux, des exemples de mauvaises calibrations dues à une mauvaise correction des darks (création de points froids et points chauds) et à une « optimisation » incorrecte du MasterDark qui corrige certes bien les pixels chauds et froids, mais ne permet pas une réduction du bruit aussi poussée que sur l’image calibrée.
Si à ce stade vos images prétraitées ne sont pas satisfaisantes, il vaut mieux reprendre les opérations précédentes afin de trouver la cause exacte des défauts constatés. La grande majorité de ces défauts sont irrécupérables par la suite au traitement et, même pour ceux qui ne sont pas totalement rédhibitoires (par exemple des petits défauts liés à une correction imparfaite des flats), ils demeureront compliqués à corriger.
Si vos images Light prétraitées vous semblent convenables, passons à l’étape suivante : la correction des petits défauts cosmétiques.
5. Correction cosmétique
Maintenant que nous disposons de nos images Light prétraitées, nous allons nous attacher à en corriger les quelques défauts résiduels à la calibration.
Ces défauts se résument essentiellement à trois aspects :
- des pixels chauds,
- des pixels froids,
- des colonnes et/ou lignes défaillantes.
La présence de pixels chauds ou froids est extrêmement fréquente sur tous les types de capteurs, y compris ceux équipés de chip de classe 1. Même pour les capteurs de classe 2, la présence de colonnes totalement mortes demeure peu fréquente ; et celle de 2 colonnes ou lignes adjacentes encore plus.
Ces défauts devraient en théorie être totalement corrigés lors de la calibration des images Lights : c’est précisément le rôle des bias, des darks et des flats... cependant, on constate souvent en pratique que cette correction n’est pas parfaite, malgré tout le soin apporté à la réalisation des fichiers de calibration.
Dans la mesure où ces défauts sont récurrents d’une image à l’autre, il est nécessaire de les corriger à ce stade afin qu’ils ne s’amplifient pas lors de l’empilement des images et créent ainsi des défauts encore plus difficiles à corriger. Par exemple un pixel « chaud » qui est décalé d’image en image avec le dithering, et qui lors de l’empilement créé un trait ou un zig-zag « chaud »…
Pour ce faire, nous allons utiliser le process CosmeticCorrection.
Entrez toutes les images Lights calibrées dans « Target Frames ».
Modifiez si nécessaire l’extension postfix (par défaut « _cc ») des images en sortie de process ainsi que le dossier de destination.
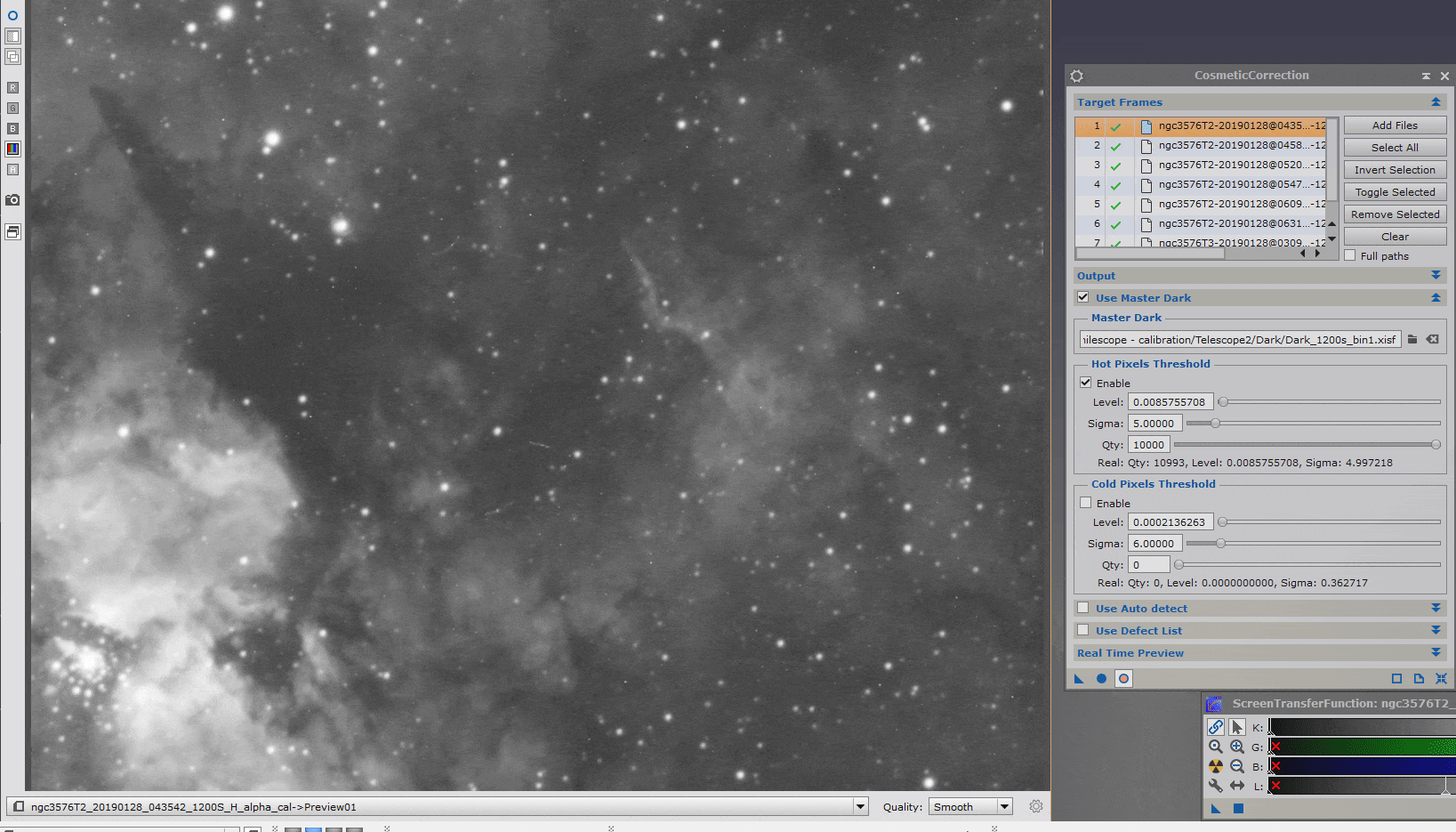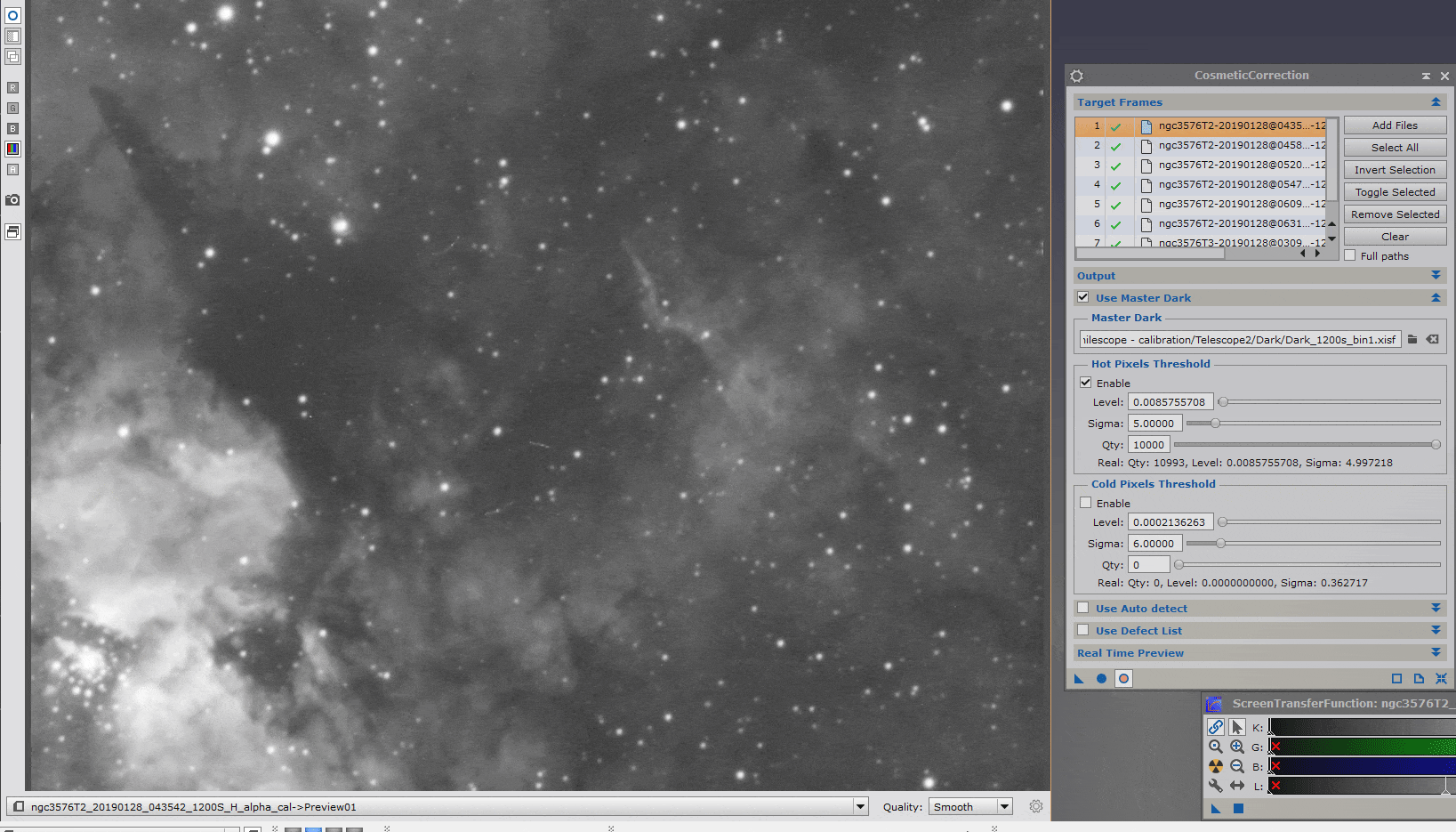
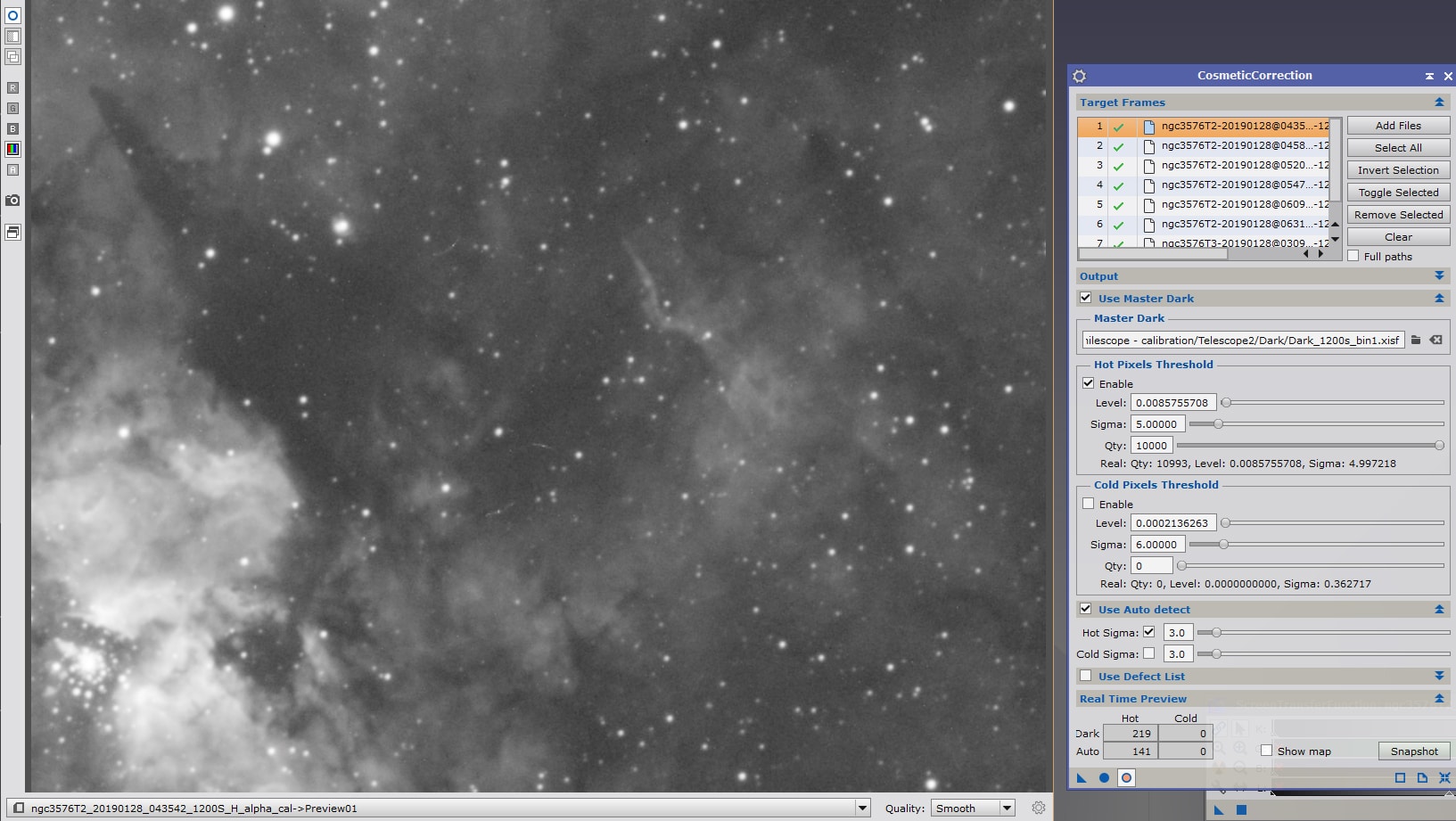
La correction des défauts cosmétiques peut être réalisée de manière totalement automatique, sur l’image dans son ensemble, à l’aide d’un algorithme de correction distinct pour les valeurs low et high, en utilisant la fonction « Use Auto Detect ».
Cependant, il est recommandé de limiter au maximum les corrections à ce stade préalable à l’empilement, et donc « d’indiquer » au process où chercher les défauts potentiels en utilisant le MasterDark.
Cochez l’option « Use Master Dark » et indiquez l’image MasterDark adéquate. Vous pouvez ensuite choisir de limiter le traitement aux seuls pixels chauds ou froids, ou aux deux types de défauts ; et en indiquant des valeurs de sigma distinctes.
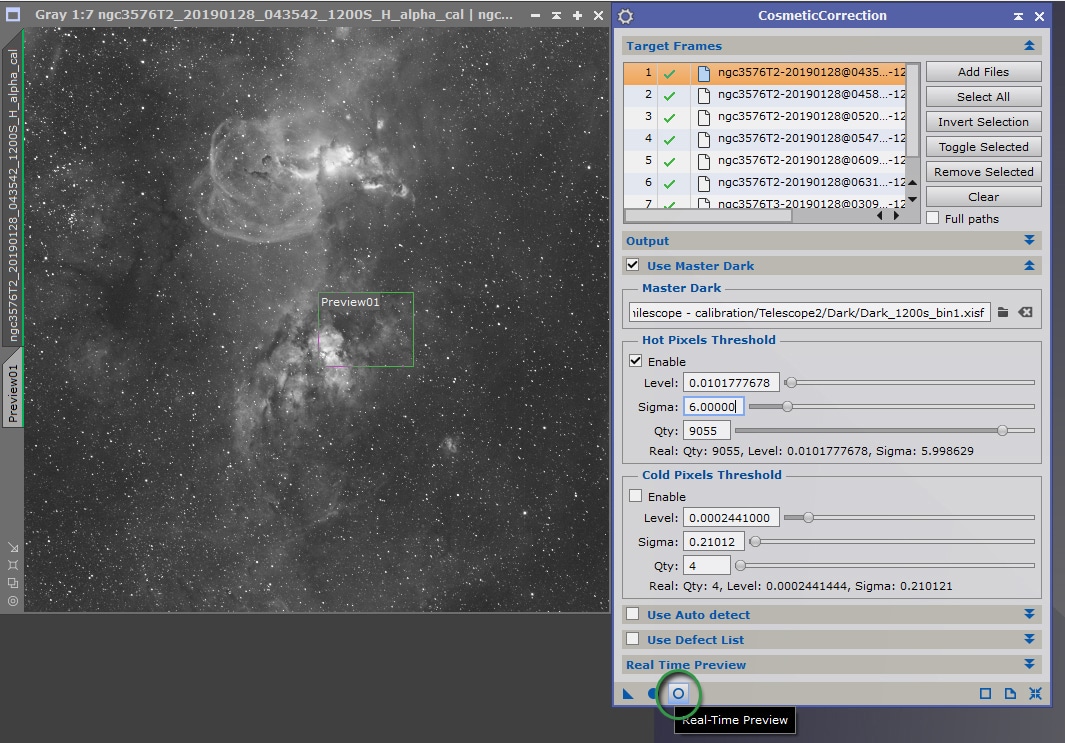
La meilleure manière de régler ces valeurs de sigma (autrement qu’en laissant par défaut des valeurs très classiques telles que 3/3, qui donnent de bons résultats), est d’ouvrir une image cible (directement depuis l’interface du process dans « Target Frames ») et en cliquant sur l’outil de Real time preview.
Sélectionnez une petite zone de l’image (Ctrl+n) pour procéder à ces réglages sur un preview en zoom 100%. La prévisualisation sur l’ensemble de l’image réduite en taille ne vous permettra pas d’apprécier la pertinence des réglages et ralentira considérablement cette phase d’ajustements.
(Sur la full, la perte de qualité est due uniquement à la compression gif utilisée pour l’animation !)
Si vous souhaitez effectuer une correction sur les pixels chauds et sur les pixels froids, il est vivement recommandé de procéder à un réglage en deux temps, en commençant par les réglages de sigma high. Une fois ces réglages effectués, procédez de même pour le sigma low. En effet, un ajustement des valeurs simultanément sera plus difficile à apprécier.
Notez que sous les barres de réglage du sigma, Pixinsight vous indique en temps réel les conséquences des modifications apportées, avec notamment le nombre de pixels corrigés. Veillez à ne pas corriger un trop grand nombre de pixels, ce qui serait le signe d’une correction trop prononcée et donc potentiellement néfaste. Ne soyez pas non plus alarmé de voir que cette étape vous conduit parfois à corriger 10 000 pixels ou plus : même sur un petit capteur contenant des millions de pixels, cela ne représente guère plus que 0,1% du total ! Il faut donc apprécier le nombre de pixels corrigés au regard du nombre total de pixels, c’est à dire la valeur en pourcentage.
Si vous n’utilisez pas de MasterDark, ou si vous n’êtes pas certain de la fiabilité de celui-ci, vous pouvez procéder à cette phase de correction en utilisant uniquement l’option « Use Auto Detect » et en effectuant les mêmes réglages que ceux décrits ci-dessus avec les valeurs de « Hot sigma » et/ou de « Cold sigma ». Utilisez de la même manière la prévisualisation pour effectuer les réglages.
Vous pouvez également utiliser la fonction « Use Auto Detect » en complément du MasterDark, afin de corriger certains défauts additionnels. Veillez dans ce cas à ce que les défauts corrigés en complément ne soient pas excessivement nombreux au regard de ceux corrigés avec l’aide du MasterDark.
Pour réparer des lignes ou colonnes défaillantes et imparfaitement corrigées lors de la calibration, ouvrez une image Light et relevez la valeur de la colonne ou de la ligne défaillante. Vous pouvez ensuite intégrer ces valeurs en cochant l’option « Use Defect List ». Notez que ces corrections se visualisent également en temps réel avec l’outil de preview.
Pour renseigner une colonne défaillante, entrez le numéro de colonne en sélectionnant « Col » et cliquez sur « Add defect ». Procédez de même pour les lignes en sélectionnant « Row ». Si les défauts n’affectent pas toute la ligne ou la colonne, il est possible de préciser des limites à la zone à prendre en compte.
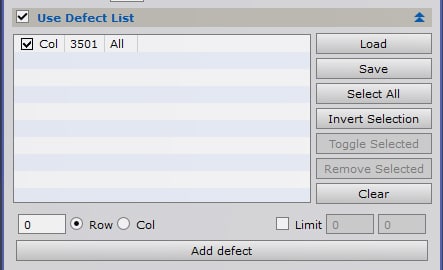
Cette opération n’est à réaliser que lors de la première opération de prétraitement : lorsque vous avez renseigné l’ensemble des défauts de colonnes et de lignes, cliquez sur « Save » afin de sauvegarder un fichier établissant la liste de ces défauts. Lors des prochains prétraitements, vous aurez juste besoin de charger le fichier correspondant en cliquant sur « Load ». Naturellement, si vous utilisez plusieurs capteurs différents pour vos acquisitions, il faudra établir un fichier pour chaque capteur et ne pas les confondre lors du chargement !
Pour vérifier avec une grande précision les corrections effectuées, ouvrez l’onglet « Real Time Preview » et cochez l’option « Show map ». Ceci vous permettra de visualiser uniquement les pixels faisant l’objet d’une correction.
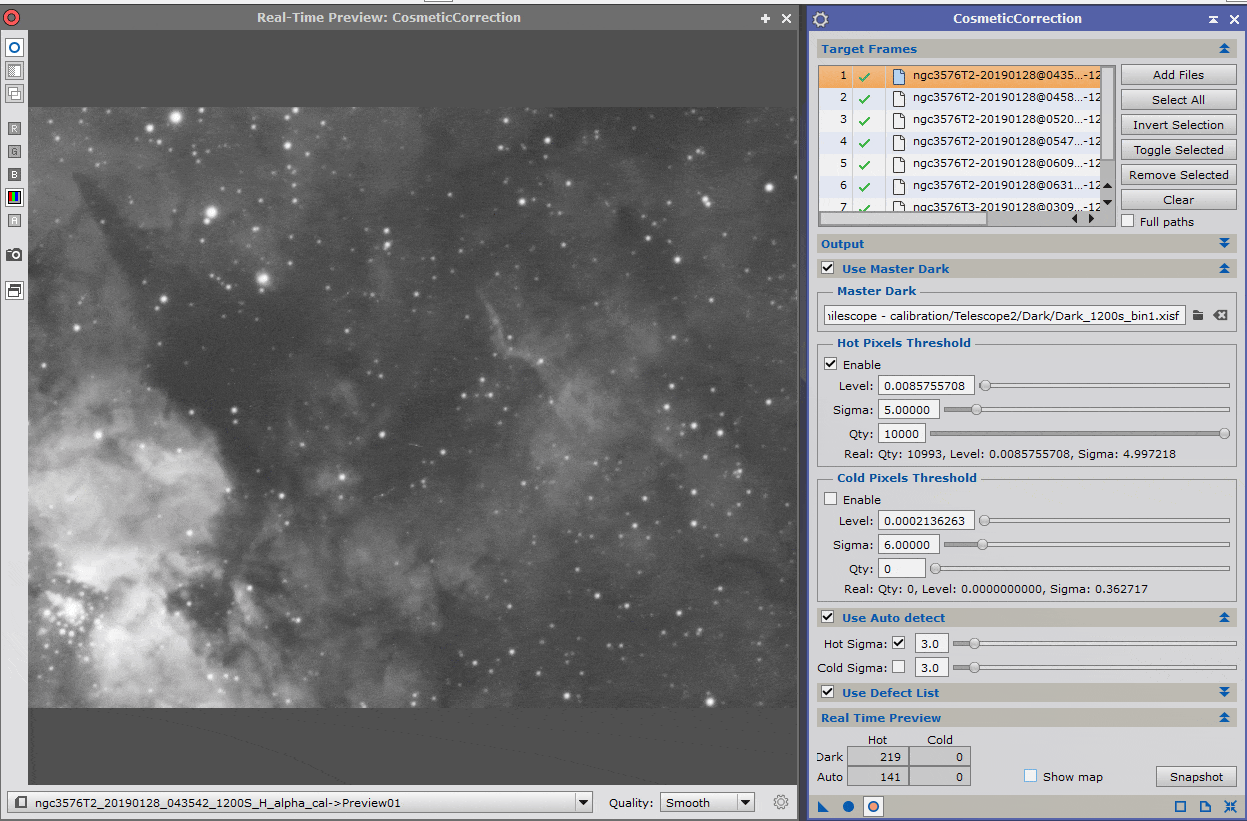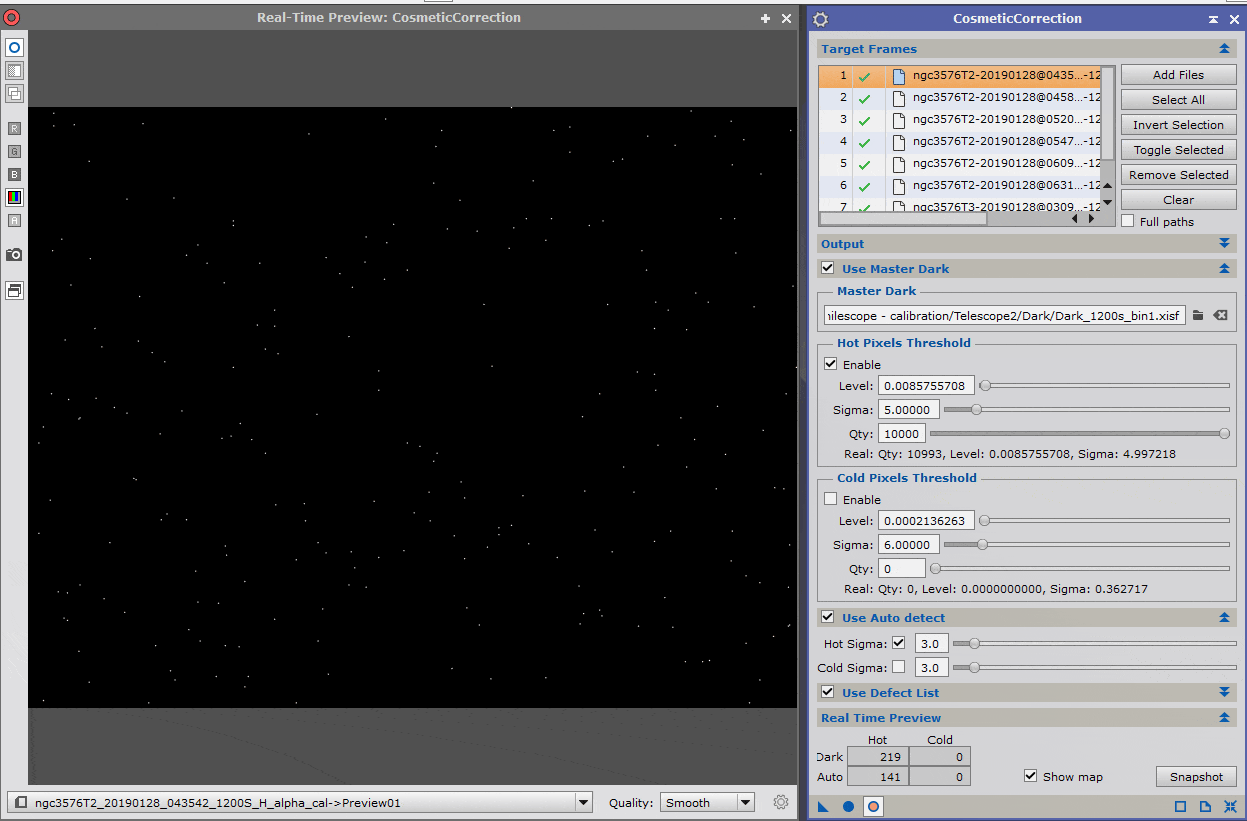
Lorsque l’ensemble de ces réglages sont effectués, lancez le process.
Le prétraitement peut se poursuivre avec ces fichiers « Light_cal_cc ».
6. Retrait de gradients
Cette étape complémentaire est l’un des plus grands atouts du prétraitement manuel avec Pixinsight. J’ai même hésité à l’inclure par défaut dans le parcours de la Piste Blanche, tant elle me semble indispensable.
Cependant, elle n’est pas réellement « indispensable » à l’obtention d’une image ; le traitement des gradients pouvant être réalisé après l’empilement des images brutes. Par ailleurs, si elle est mal réalisée, cette opération peut apporter plus de mal que de bien à l’image empilée ; obligeant alors à une reprise globale du prétraitement et à une perte de temps importante. Il m’a donc semblé légitime de la proposer dans le parcours de la Piste Bleue.
L’intérêt de procéder au retrait des gradients avant empilement
Si vous avez déjà effectué quelques traitements d’images, vous avez pu vous rendre compte que le retrait des gradients est l’une des étapes les plus difficiles à réaliser correctement. En effet, bien que les outils proposés par Pixinsight (ABE et DBE) soient très puissants, ils peuvent s’avérer délicats à paramétrer pour obtenir un résultat satisfaisant.
Le retrait des gradients est en effet une opération subtile, qui implique la prise en compte d’un grand nombre de paramètres : la modélisation du fond de ciel, les valeurs à inclure et à exclure, la tolérance de l’algorithme, le mode de retrait du gradient, etc.
Par ailleurs, au-delà des aspects strictement liés à la configuration des process, certaines difficultés sont liées aux images elles-mêmes : certains gradients sont facilement identifiables, d’autres non… sur certaines images, il peut s’avérer particulièrement difficile de distinguer un gradient d’une nébulosité très ténue ou du fond de ciel. Le risque est alors de prendre en compte dans la modélisation du gradient certains éléments qui n’en sont pas : IFN, nébulosités, etc. Et ce faisant, de parvenir à un résultat incorrect qui détériore irrémédiablement l’image finale.
Pour ne rien arranger, la correction des gradients sur l’image empilée propose une autre difficulté : les gradients évoluent d’une image brute à l’autre. En effet, la prise de vue s’étalant le plus souvent sur plusieurs heures, voire plusieurs nuits (et parfois depuis différents sites…), l’objet photographié bouge dans le ciel et n’est pas affecté de la même manière par les différentes sources de gradients : pollution lumineuse, présence de la Lune qui elle-même bouge par rapport à l’objet, etc.
Il en résulte que, lors de l’empilement, la combinaison des différentes images brutes est réalisée en intégrant également ces différents halos disparates, pour former au final une image contenant un halo « global » particulièrement complexe à bien modéliser.
Pour améliorer le résultat, l’idée est donc de traiter séparément et préalablement à leur empilement chacune des images Light.
La méthodologie retenue
Pour que cette opération puisse être réalisée de manière efficace et suffisamment rapide, il va falloir procéder à quelques choix de compromis en privilégiant des process permettant un traitement fiable et automatique du plus grand nombre d’images. Il n’est, en effet, pas envisageable de consacrer à ce stade une dizaine de minutes par image pour procéder à un retrait de gradient personnalisé et optimisé !
L’objectif est de procéder au retrait des gradients les plus évidents et les plus simplement modélisables ; quitte à sous-corriger légèrement. Il sera en effet toujours possible de procéder à un autre retrait de gradients sur l »image empilée, pour laquelle l’essentiel du travail aura déjà été fait.
Autrement dit, on ne cherche pas ici à atteindre la perfection absolue mais un résultat très amélioré en utilisant des moyens simples et rapides ; et qui pourra être optimisé par la suite lors du traitement.
Pour ces raisons, je recommande d’utiliser à ce stade le process ABE. Simple et rapide à configurer, il donne déjà d’excellents résultats et corrige l’essentiel des défauts de gradients avant l’empilement. Le process DBE sera quant à lui utilisé plus tard, lors du traitement, pour procéder à un retrait plus fin des éventuels résidus de gradients sur l’image empilée.
Création de « lots » d’images Light
La première étape va consister à réunir toutes les images Light concernées par un même retrait de gradient au sein d’un conteneur d’images.
Dans la mesure où nous allons ensuite appliquer un process identique (mêmes paramètres) à l’ensemble des images du conteneur, il est primordial de bien veiller à créer si besoin autant de conteneurs d’images que de sessions d’acquisition.
Par exemple, si les images brutes ont été réalisées sur 3 nuits différentes, il faut créer 3 conteneurs d’images distincts afin de leur appliquer éventuellement des process de retrait de gradient personnalisés. Si les acquisitions ont été réalisées lors d’une seule session, l’ensemble des images Light seront réunies au sein du même conteneur.
Notez qu’à ce stade, nous ne préjugeons pas des réglages de retrait de gradient : nous prévoyons simplement la possibilité qu’ils soient différents ! Mais, dans l’idéal, nous essaierons d’appliquer à l’ensemble des images devant être empilées les mêmes paramètres de retrait de gradient…
Lancez le process « ImageContainer ».
Cliquez sur l’icone « ajoutez des fichiers » (encadré en rouge dans l’exemple ci-contre) et sélectionnez l’ensemble des images Light à intégrer à ce conteneur.
Vous pouvez personnaliser également les répertoires et noms de sortie des images après leur traitement.
A titre personnel, c’est à ce stade que je réunis l’ensemble de mes images Light issues de différentes sessions sous un seul et même répertoire « Light », car les traitements ultérieurs ne seront plus différenciés après cette opération.
Réglez l’option « On Errors » sur « Continue execution ».
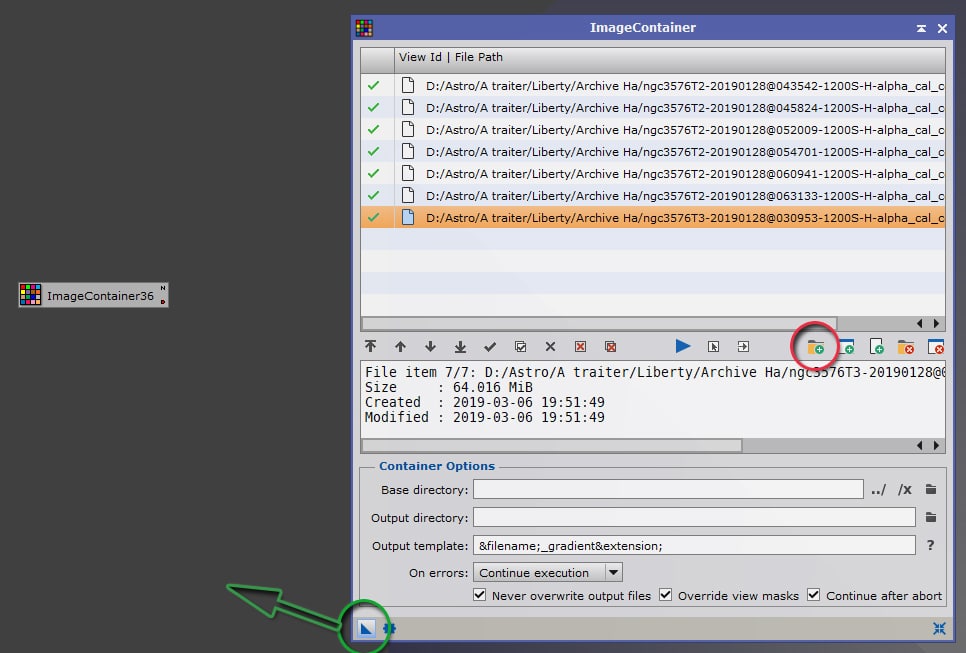
Une fois ces opérations effectuées, cliquez et maintenez l’icone « New Instance » (triangle dans la barre inférieure de la fenêtre du process encadré en vert ci-contre) et déposez le en le relâchant dans la zone de travail principale de Pixinsight.
Un icone est créé, représentant le conteneur d’images.
Répétez cette opération autant de fois que de conteneurs d’images sont nécessaires.
Vous pouvez ensuite passer à l’étape de retrait de gradients avec ABE ou DBE expliquées ci-dessous.
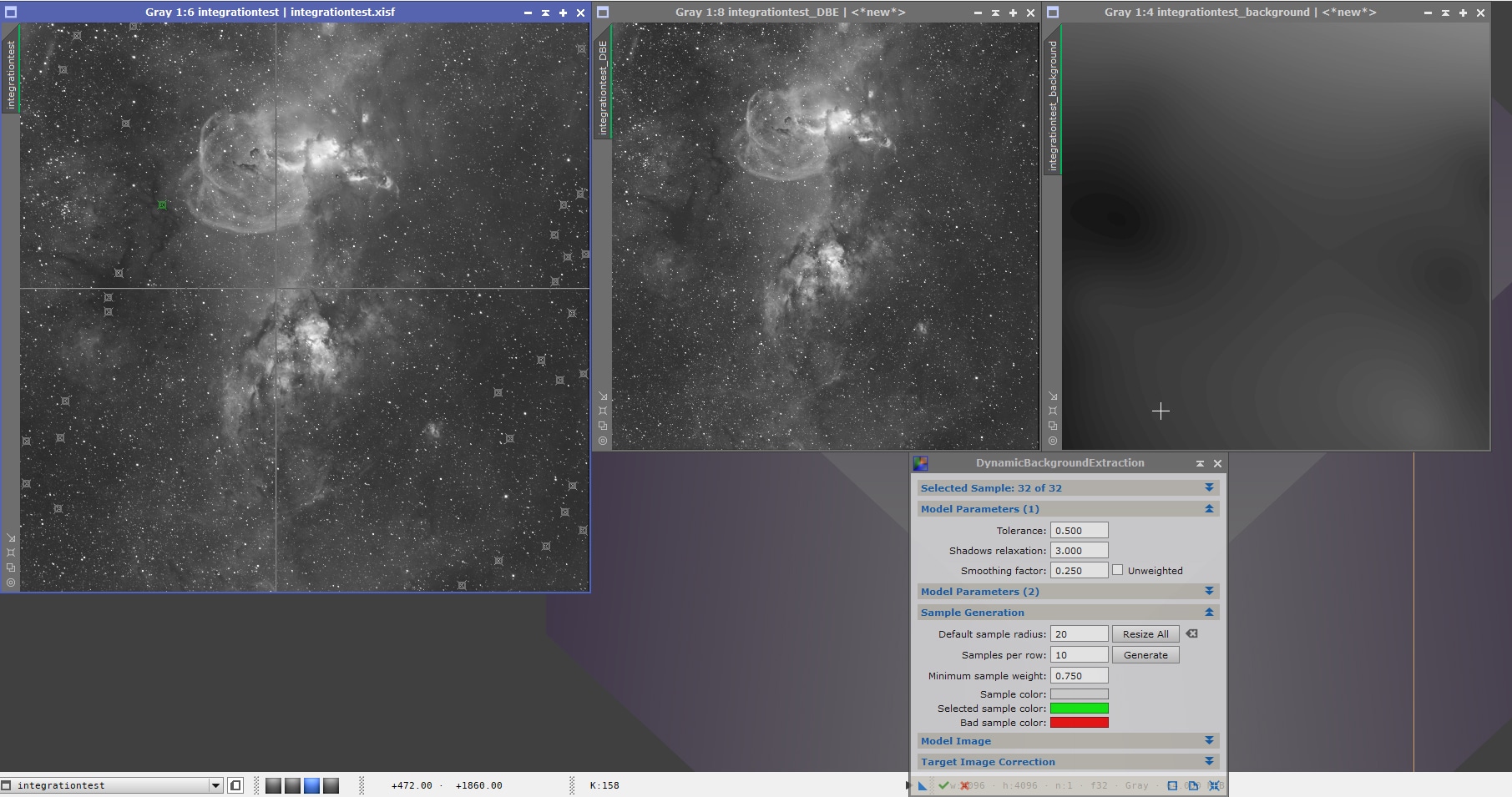
Méthode recommandée : retrait de gradients automatique avec ABE
Pixinsight propose deux process très puissants de retraits de gradients : ABE et DBE, qui fonctionnent tous les deux sur les mêmes algorithmes mais qui ne proposent pas les mêmes options de personnalisation, notamment dans la modélisation des gradients.
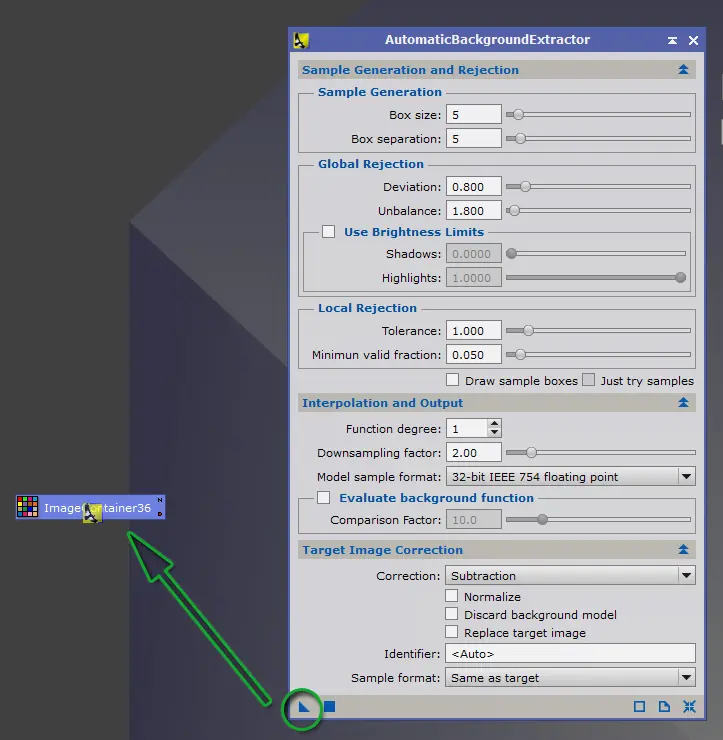
ABE (« Automatic Background Extractor ») est de loin le plus simple à utiliser des deux : sur la base de quelques paramètres, ce process va modéliser les gradients automatiquement, sans qu’il soit nécessaire de préciser un par un les points d’échantillonnage pertinents.
Revers de la médaille : les modélisations obtenues sont moins finement ajustées qu’avec DBE. Il n’est pas possible, par exemple, d’inclure ou d’exclure spécifiquement tel ou tel échantillon pour la création de l’image de gradients.
Toutefois, ce process est ici idéal compte-tenu de notre objectif sur cette phase de prétraitement : simplicité et rapidité, sans recherche d’un résultat optimal.
La première étape, avant de procéder au traitement par lots, est de déterminer les réglages pertinents sur l’une des images de ce lot.
Lancez le process AutomaticBackgroundExtractor (ABE) et ouvrez l’une des images Lights intégrées dans le conteneur objet de ce traitement.
Pour commencer, vous pouvez utiliser les paramètres par défaut, notamment ceux de « Sample Generation and Rejection ».
Ces paramètres déterminent les caractéristiques de création des échantillons utilisés pour la modélisation : la taille et l’espacement en pixels de l’échantillonnage, la « déviation » et la « tolérance » par rapport à l’écart-type (mesuré en sigma) utilisés pour les réjections. Nous en dirons quelques mots par la suite mais, à ce stade, nous pouvons laisser les paramètres par défaut.
Dans « Target Image Correction », sélectionnez « Substraction » pour le mode de correction, et laissez décochées les options proposées en dessous.
Le paramètre qui va nous intéresser le plus ici est « Function Degree » dans « Integration and Output ».
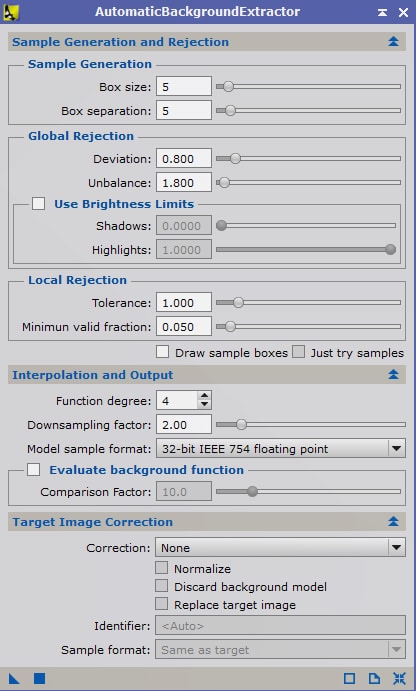
De manière simplifiée, le nombre indiqué pour le paramètre « function degree » détermine le degré du polynôme utilisé pour la modélisation du fond de ciel : un degré de 1 générera uniquement des gradients « linéaires », un degré de 2 prendra en compte les aspects circulaires, et les degrés supérieurs généreront des gradients de plus en plus complexes (circulaires, avec de multiples dégradés dans différentes directions, etc.).
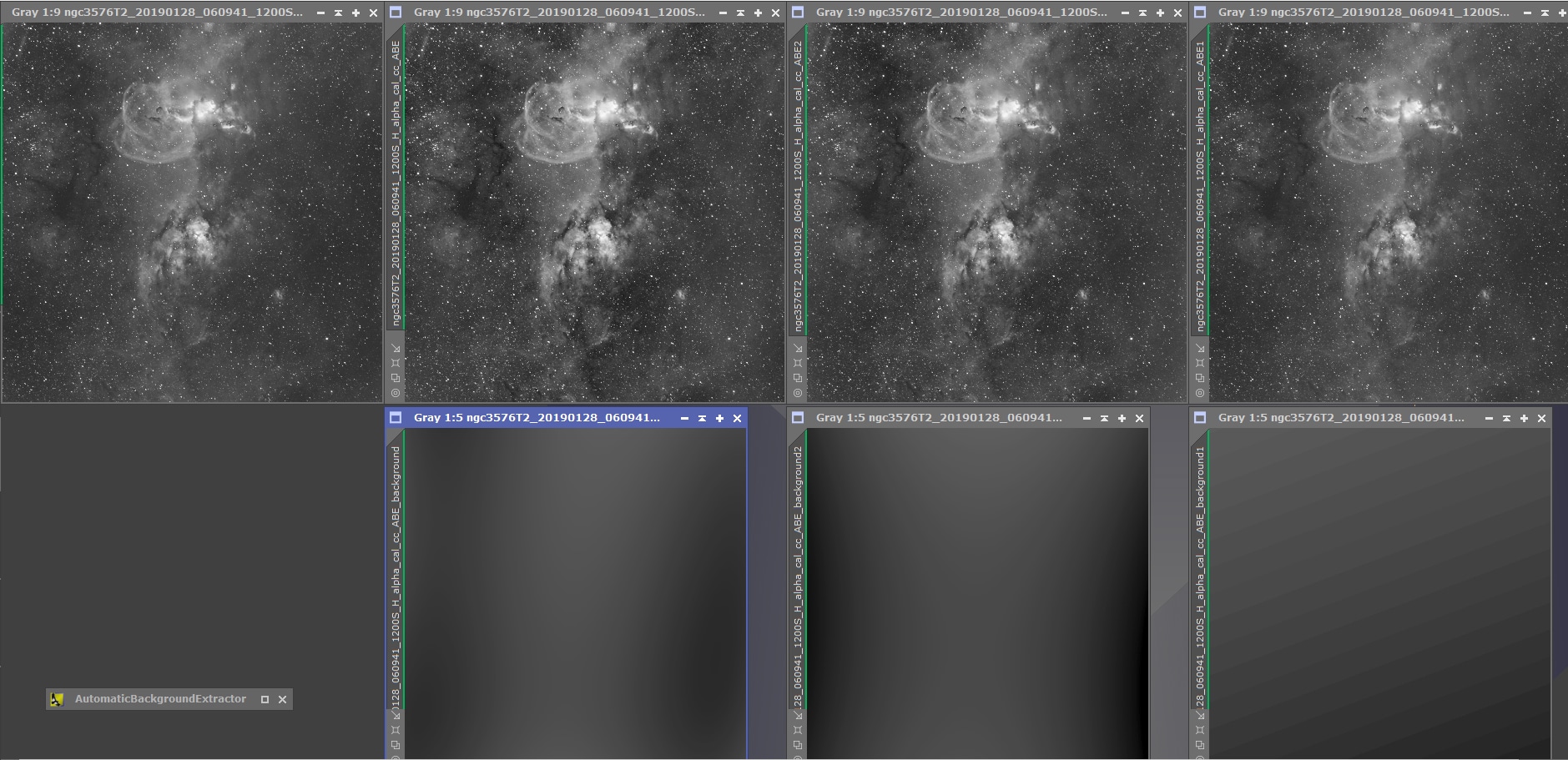
A chaque image finale (en haut) est associée la modélisation de gradient qui a été soustraite (en bas).
Notez que sur cette image, le meilleur résultat est obtenu avec la modélisation la plus simple (degré 1, à droite), qui ne tient aucun compte des objets présents sur l’image.
En pratique, pour le retrait de gradient réalisé à ce stade, il est recommandé de conserver une modélisation de gradients de niveau 1 si l’image contient une nébuleuse ou des galaxies.
Une modélisation de ce type ne permet certes pas un retrait total de tous les gradients (qui sont souvent d’apparence légèrement circulaires en fonction de la focale utilisée), mais cet inconvénient est plus que compensé par l’absence de prise en compte des objets du fond de ciel qui en résulte dans la modélisation.
Le fait que les objets du fond de ciel (galaxies, nébuleuses…) ne soient pas pris en compte dans la modélisation est en effet essentiel à un retrait de gradient réussi.
A défaut, les zones où les objets sont présents vont être considérés comme du gradient, et le process va procéder à un retrait dans ces zones.
Il en résulte une sorte de « halo » plus foncé autour des objets sur l’image obtenue par ce traitement. Ce « halo » est parfaitement visible pour un œil exercé, et est très difficile à rattraper ensuite lors du traitement. C’est le signe le plus visible d’un retrait de gradient mal réalisé.

Sur l’exemple ci-dessus, on voit les différences apportées par les retraits de gradients selon le degré retenu.
Le degré 1 permet le plus souvent de ne pas altérer le signal de l’objet et de ses alentours, par la seule soustraction du gradient du à la présence de la Lune lors de l’acquisition.
Attention toutefois, si le champ ne contient aucune nébulosité ou galaxies, dans le cas par exemple un amas ouvert, des degrés supérieurs peuvent souvent être utilisés sans générer d’artefacts de traitement. Si cela est possible, privilégiez ces degrés supérieurs qui permettront une modélisation plus précise des gradients.
Une fois le degré de « Function degree » retenu, vous pouvez procéder à des essais complémentaires pour affiner encore mieux le retrait de gradient. Par exemple en jouant avec les valeurs de « déviation » et de « tolérance ». Notez toutefois que les valeurs par défaut (celles renseignées dans l’exemple de ce tuto) donnent le plus souvent – pour la démarche adoptée ici – de très bons résultats.
Les réglages de « tolérance » et « déviation » affectent la force de la réjection effectuée ; les valeurs sont exprimées en « sigma », c’est à dire la déviation des pixels par rapport à l’écart-type.
En diminuant ces valeurs, vous forcez l’algorithme de réjection a être plus sélectif, et même de petits écarts avec le niveau de fond de ciel conduiront à exclure les échantillons. Ceci est indiqué pour éviter d’inclure sur la modélisation des gradients certaines zones de nébuleuses ténues, comme dans l’exemple présenté ici.
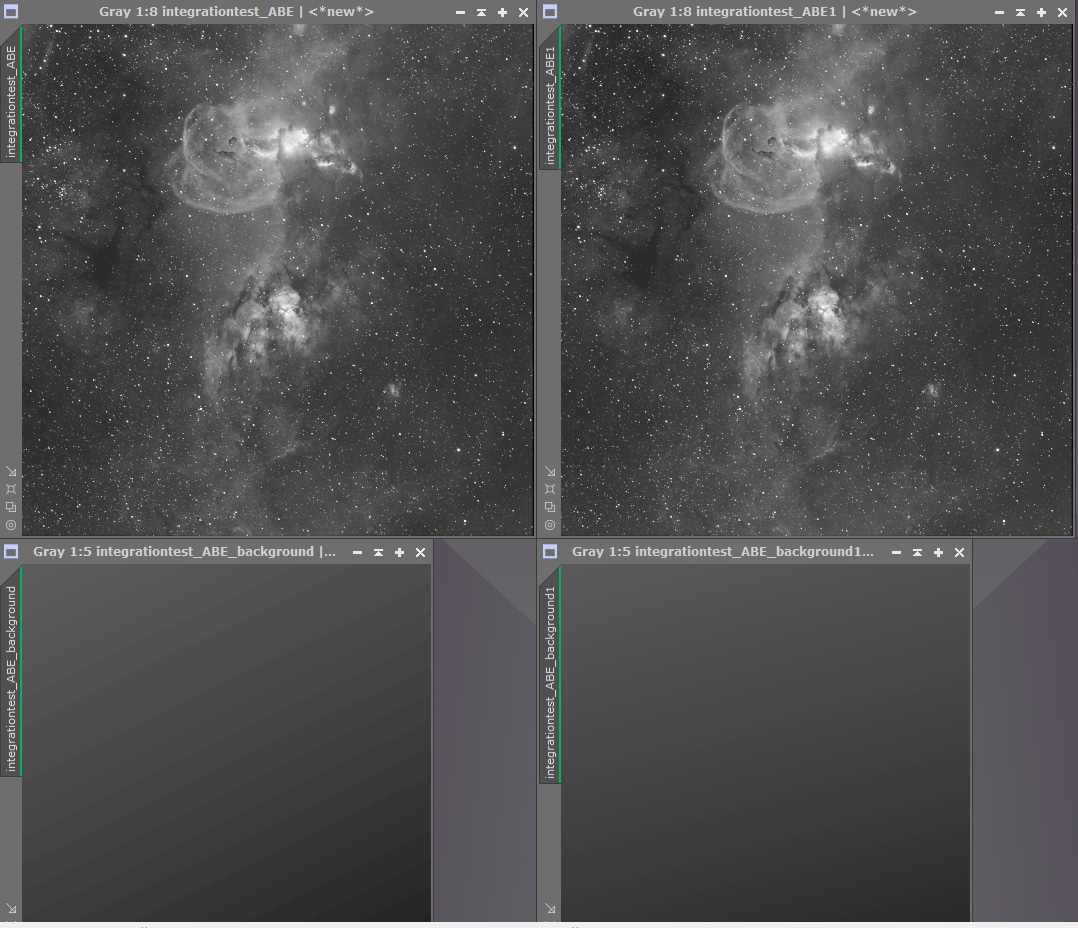
Une fois tous les réglages effectués, appliquez le process sur le conteneur d’images (en déplaçant l’icone triangulaire « New Instance » du process sur l’icone du conteneur) : le process va ainsi être appliqué avec les mêmes paramètres à toutes les images intégrées préalablement au conteneur.
L’avantage d’utiliser la fonction ABE est ici flagrante : peu importe que les images soient précisément alignées pour réaliser ce retrait de gradient : le process va générer lui-même les points d’échantillonnage sur l’image et s’adapter à chaque image. Beaucoup plus simple que si nous avions fixé les points d’échantillonnage manuellement avec DBE !
L’ensemble des images traitées, ainsi que la modélisation du fond de ciel associé, est affichée directement dans l’espace de travail.
Avant d’aller plus loin, vérifiez donc que les images obtenues et les modélisations associées sont cohérentes.
Répétez au besoin cette opération pour chacun des différents conteneurs d’images que vous avez créé. Privilégiez si possible des paramètres identiques ou proches.
A ce stade, comme nous l’avons vu, nous ne cherchons pas à procéder à un retrait de gradient parfait ; mais seulement à corriger les images des défauts les plus importants avant leur empilement. Inutile donc de procéder à une « double-passe » de retrait de gradient sur les images.
Une fois ces opérations réalisées, il est possible de passer à l’étape suivante de sélection et de pondération des Lights (étape 7).
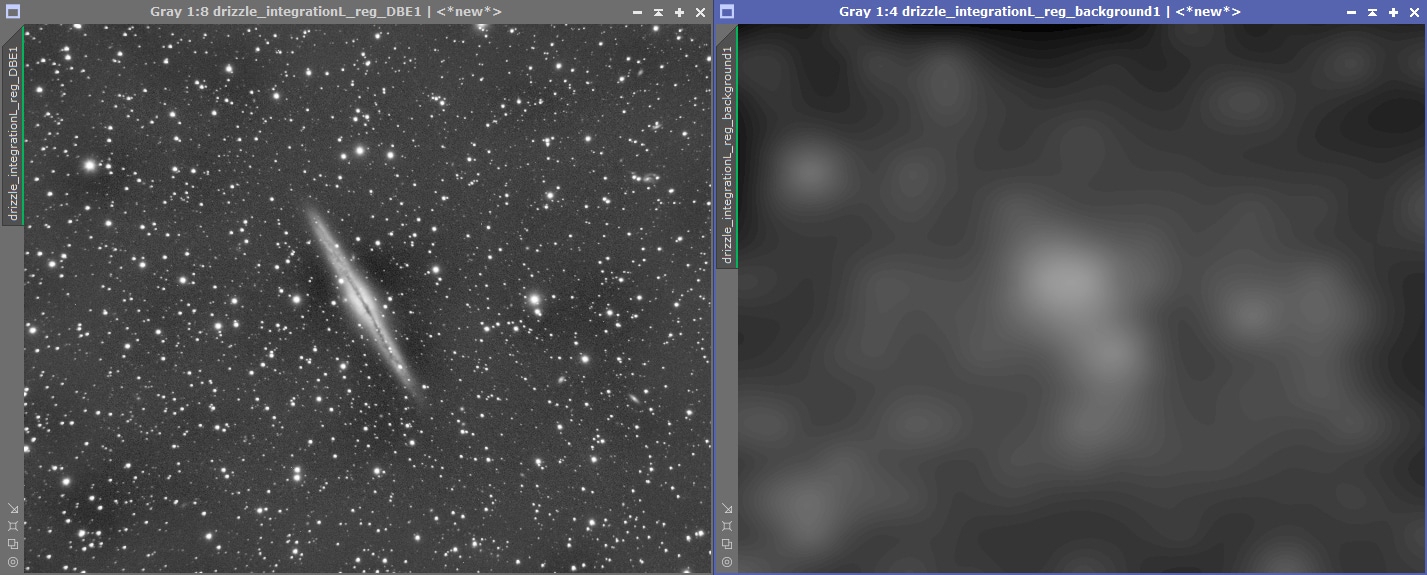
Méthode alternative : retrait de gradients optimisé avec DBE
DBE (Dynamic Background Extraction) repose sur les mêmes principes que ABE, mais offre une totale personnalisation des options de modélisation. Elle permet en particulier à l’utilisateur de définir précisément les points d’échantillonnage qui vont être utilisés pour la modélisation des gradients, d’en supprimer certains ou d’en ajouter d’autres…
Son utilisation est donc plus complexe que ABE car les risques d’erreurs sont plus importants : aucun point d’échantillonnage ne doit se situer dans des zones de nébulosités ou sur des étoiles : seul les zones de pur fond de ciel sont à prendre en compte.
Cependant, bien configurée, les résultats seront le plus souvent plus précis qu’avec ABE. Dans certains cas même, un retrait des gradients complexes ne sera possible qu’avec DBE ! Revers de la médaille : outre le risque d’erreurs plus important, ce process est bien plus long à configurer sur certaines images que ABE ; c’est pourquoi je ne recommande pas son utilisation au niveau du prétraitement ; mais plutôt lors du traitement de l’image empilée.
Si toutefois vous ne jurez que par DBE (ce qui peut se comprendre !), vous pouvez réaliser l’opération de gradients à ce stade avec ce process. Attention toutefois : cela implique à mon sens d’avoir déjà une certaine expérience de traitement et une bonne connaissance de cet outil et de ses subtilités. C’est pour cette raison que cette méthode alternative est intégrée à la « Piste Rouge » !
Avant de commencer, effectuez la même sélection d’images par lots avec ImageContainer que celle décrite dans la Piste Bleue ci-dessus.
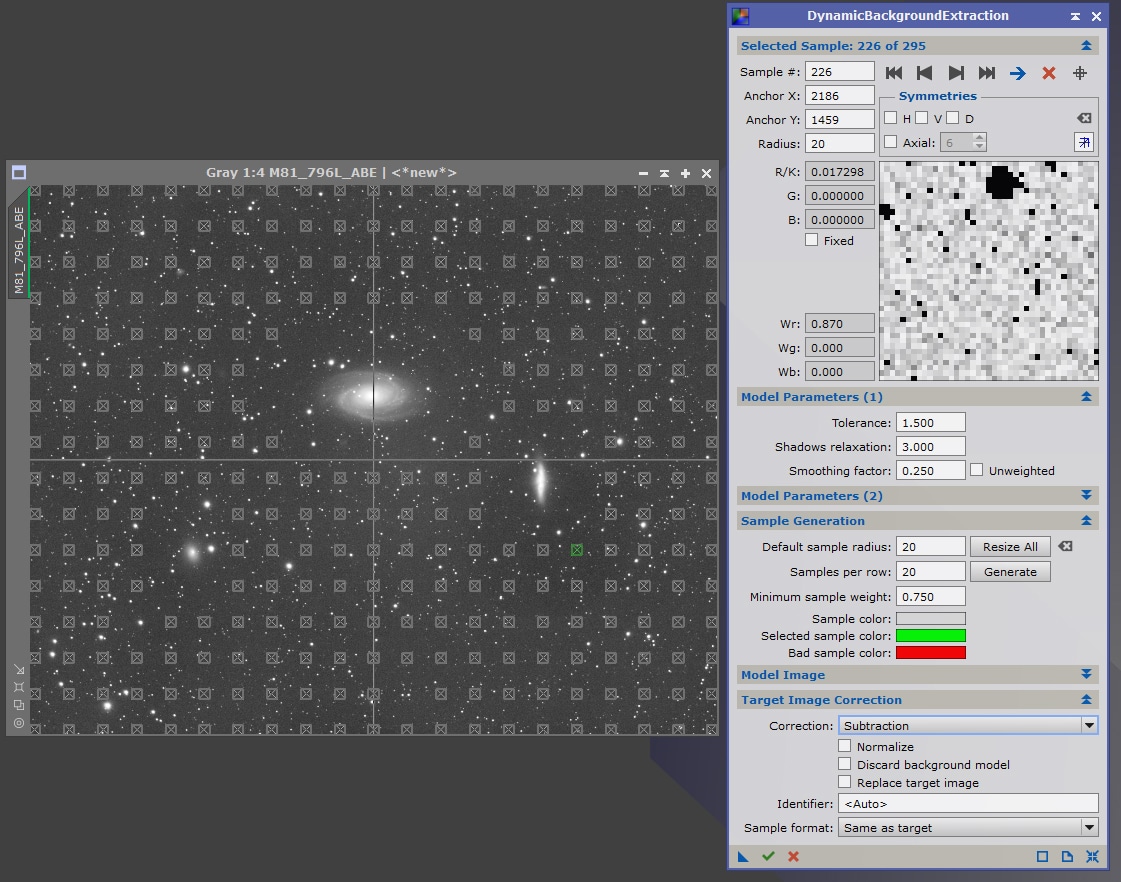
Lancez le process DBE et ouvrez une image Light intégrée dans le conteneur d’images. Vérifiez que les réglages de DBE sont bien ceux par défaut en cliquant avant toute chose sur le bouton « Reset » en bas à droite de la fenêtre de process.
La première étape est de définir les valeurs des zones d’échantillonnage, avec les paramètres « Default sample radius » et « Samples per raw ». Ceux utilisés par défaut sont souvent très petits et mal adaptés, n’hésitez pas à prévoir davantage de zones de plus grande taille.
Si cela est possible, car la zone de gradient est bien définie et présente une zone centrale, centrez la croix présente sur l’image sur le centre du gradient.
Cliquez ensuite sur « Generate » : les zones d’échantillonnage s’affichent sur l’image. Si ces zones ne sont pas adaptées (trop ou trop peu nombreuses, zones pertinentes non couvertes ou zones de nébuleuses couvertes…), il vous faut modifier les paramètres d’inclusion dans « Model Parameters ».
Ajustez « Tolerance » (exprimé en sigma) pour définir la déviation maximum autorisée par rapport à l’écart-type (diminuez pour être plus restrictif), ainsi que « Shadows relaxation » (augmentez la valeur pour mieux prendre en compte les zones noires). Cliquez sur « Generate » pour voir les modifications apportées.
Attention : des paramètres trop tolérants conduiront à inclure des nébulosités dans la modélisation, tandis que des paramètres trop restrictifs conduiront à appauvrir la modélisation du fond de ciel… il convient donc de trouver un compromis plutôt « moins restrictif » que trop « restrictif ».
Une fois ces paramètres définis, procédez à de légers ajustements et ne cliquez pas sur « Generate » mais sur « Resize all » : les zones ne resteront au-même endroit, mais seront actualisées avec les nouveaux paramètres : cela permet de visualiser en temps réel les zones « bonnes » et les zones « incorrectes », qui s’affichent en rouge ; sans perdre l’emplacement des échantillons.
Procédez ensuite à une sélection manuelle des zones d’échantillon, en déplaçant celles déjà créées, en les supprimant ou en les ajoutant si besoin. Pixinsight vous indique en temps réel les échantillons ne répondant pas aux paramètres que vous avez renseigné.
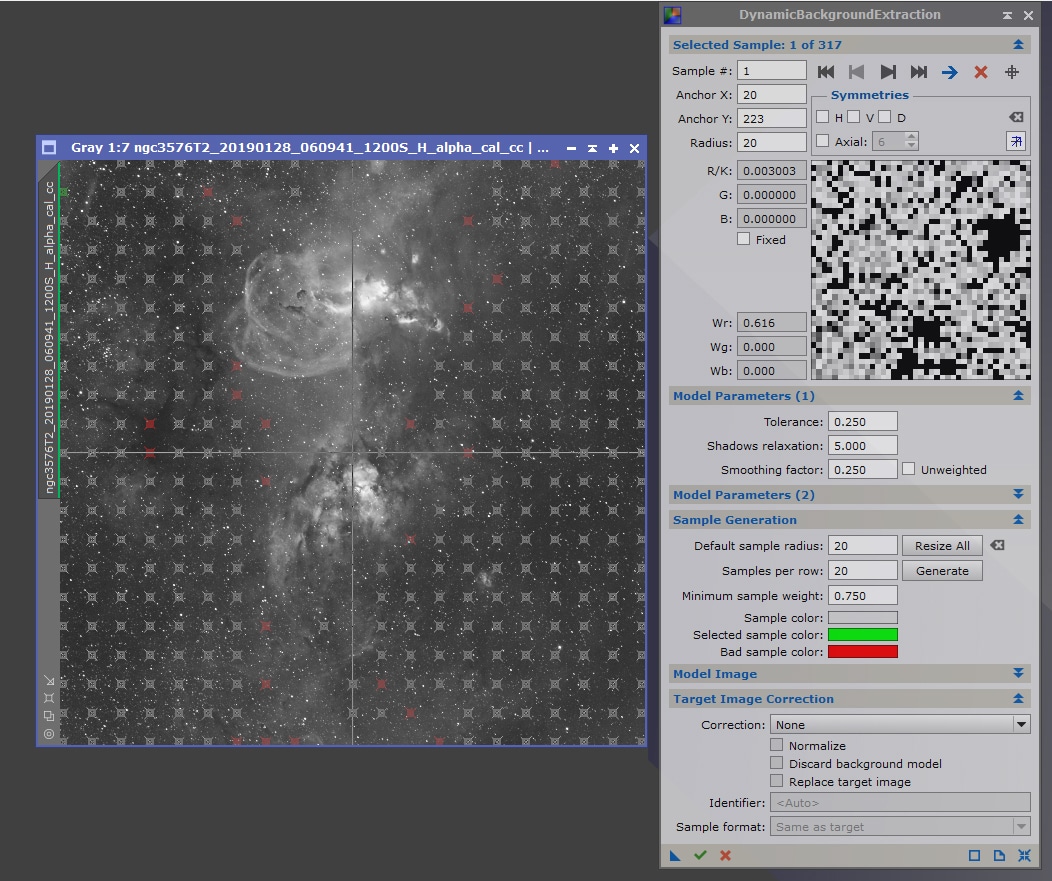
Les échantillons non pertinents sont indiqués en rouge.
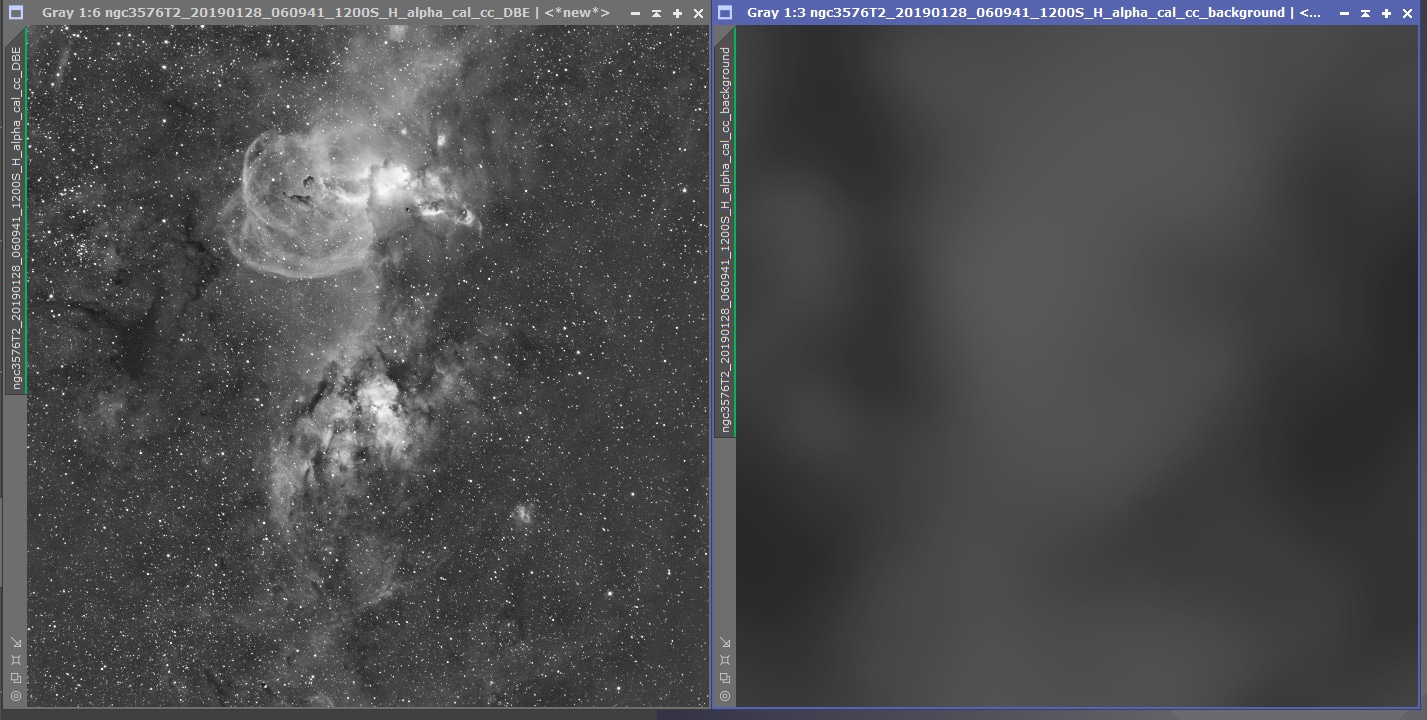
Lorsque ces opérations sont réalisées, lancez le process pour voir le résultat. Sélectionnez le mode « soustraction » et laissez décochées les autres options dans « Target Image Correction ».
Si le résultat vous convient, vous pouvez appliquer le process à l’ensemble des images en exécutant le process sur l’icone « Image Container » créé précédemment.
Attention, dans la mesure où les zones d’échantillonnage ont été définies de manière précise sur une image particulière et qu’un léger décalage peut se produire entre chaque image d’une même série (ne serait-ce qu’en raison du dithering), il convient de vérifier avec attention que la correction par lots ne contient pas d’erreurs flagrantes sur chacune des images corrigées.
Une fois ces vérifications effectuées, répétez si besoin l’opération pour les éventuels autres conteneurs d’images ; et passez à l’étape suivante.
Note : Les quelques réserves exprimées ci-dessus ne concernent que l’utilisation du process DBE dans le cadre du prétraitement, qui me semble beaucoup plus compliquée à mettre en oeuvre que ABE, pour des résultats pas toujours fiables…
Cela est vrai en particulier pour les images ne contenant que très peu (voire pas du tout) de zones de fond de ciel pur.
En revanche, il existe des cas dans lesquels le process DBE demeurera très simple à utiliser et sans risques d’erreurs ; par exemple pour les images principalement composées de fond de ciel avec des objets bien délimités, tels que les galaxies.
Dans l’exemple ci-contre, on voit immédiatement que le positionnement des zones d’échantillonnage ne pose guère de difficultés et que la modélisation de gradient est correcte, sans prendre en compte la galaxie au centre de l’image.
Attention cependant à ne pas positionner les zones d’échantillonnage trop près de l’objet principal : cela générera des halos sombres autour de l’objet, parfois très visibles, parfois difficilement perceptibles avant de passer en mode non-linéaire ; mais dans tous les cas très disgracieux et difficiles à corriger lors du traitement.
Autre cas de figure particulier et moins trivial : que faire en cas de présence d’IFN dans le champ ?
L’IFN (sortes de « cirrus galactiques ») est le plus souvent quasiment imperceptible sur les brutes et ne se révèle que lors de l’empilement, voire du traitement…
A moins de connaître précisément le champ photographié et de s’aider de prises de vues existantes, il est donc difficile de paramétrer au mieux DBE sans intégrer cet IFN dans la modélisation du fond de ciel.
Un autre risque est également, si l’on ignore la présence d’IFN dans le champ, de retirer une grande partie de son signal lors de cette phase de retrait de gradient… sans même s’en rendre compte !
Dans tous les cas de figure où vous avez une incertitude quant à la pureté du fond de ciel, à la présence de nébulosité ou encore d’IFN, il est donc recommandé de privilégier la modélisation par ABE.

Pour conclure, voici une comparaison entre les résultats obtenus avec ABE et DBE, sur une image constituant un cas « simple ». Ici encore, avantage à ABE : les gradients sont très similaires, mais il a suffit de quelques secondes pour procéder au paramétrage et au traitement.

7. Sélection et pondération des images Light
Avant de procéder à l’alignement puis à l’empilement des images Light, nous allons prendre quelques secondes pour déterminer quelles sont les meilleures images réalisées, qui serviront ensuite d’image « de référence ».
Pour ce faire, nous allons utiliser le process « Subframe Selector ». Si votre version de Pixinsight est à jour (version 1.8.6), cet outil a été intégré aux process du logiciel et ne figure désormais plus dans les scripts. Si votre version est plus ancienne, vous trouverez donc cette fonction dans les scripts… et profitez-en pour faire une mise à jour ! 🙂
Réglages de Subframe Selector
Pour visualiser les résultats mesurés avec des mesures correctes, prenez quelques instants pour renseigner au préalable les champs « Subframe scale »(échantillonnage) et « Camera gain » ; en veillant à ce que les options « Scale unit » et ‘Data unit » soient bien configurées, respectivement sur « arcsec » et sur « electron » (e- par ADU). Précisez également la qualité de numérisation de votre caméra (le plus souvent 16bits pour les caméras dédiées au ciel profond…).
Pour rappel, l’échantillonnage (en secondes d’arc par pixel) se calcule très simplement avec la formule suivante :
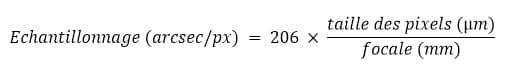
Par exemple, pour les images d’exemple de ce tutoriel, les pixels de la caméra mesurent 9µm et la focale de l’instrument est de 1850mm. L’échantillonage à renseigner dans le process est donc de (206 x 9)/1800= 1″/px.
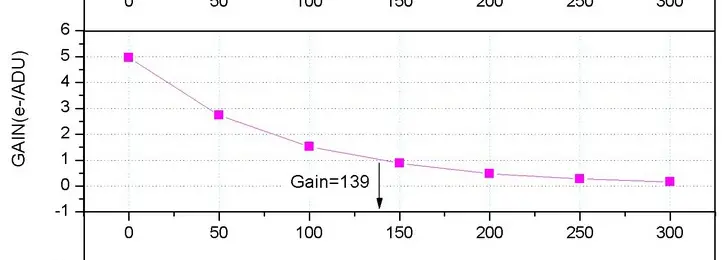
Le gain de la caméra, quant à lui, peut être déterminé à partir de mesures réalisées directement sur les images issues de votre caméra. L’excellent site Lightvortex propose un tutoriel très complet à ce sujet. Vous pouvez également retrouver cette information sur la documentation technique de votre caméra fournie par le fabricant.
Pour les caméras CCD, le gain est fixe. Vous pouvez donc rentrer la valeur une fois pour toutes et sauvegarder le process afin de conserver cette valeur pour les prochains traitements.
Pour les CMOS, le gain est réglable par l’utilisateur. Veillez donc à bien indiquer la valeur utilisée lors de l’acquisition pour la série d’image traitée.

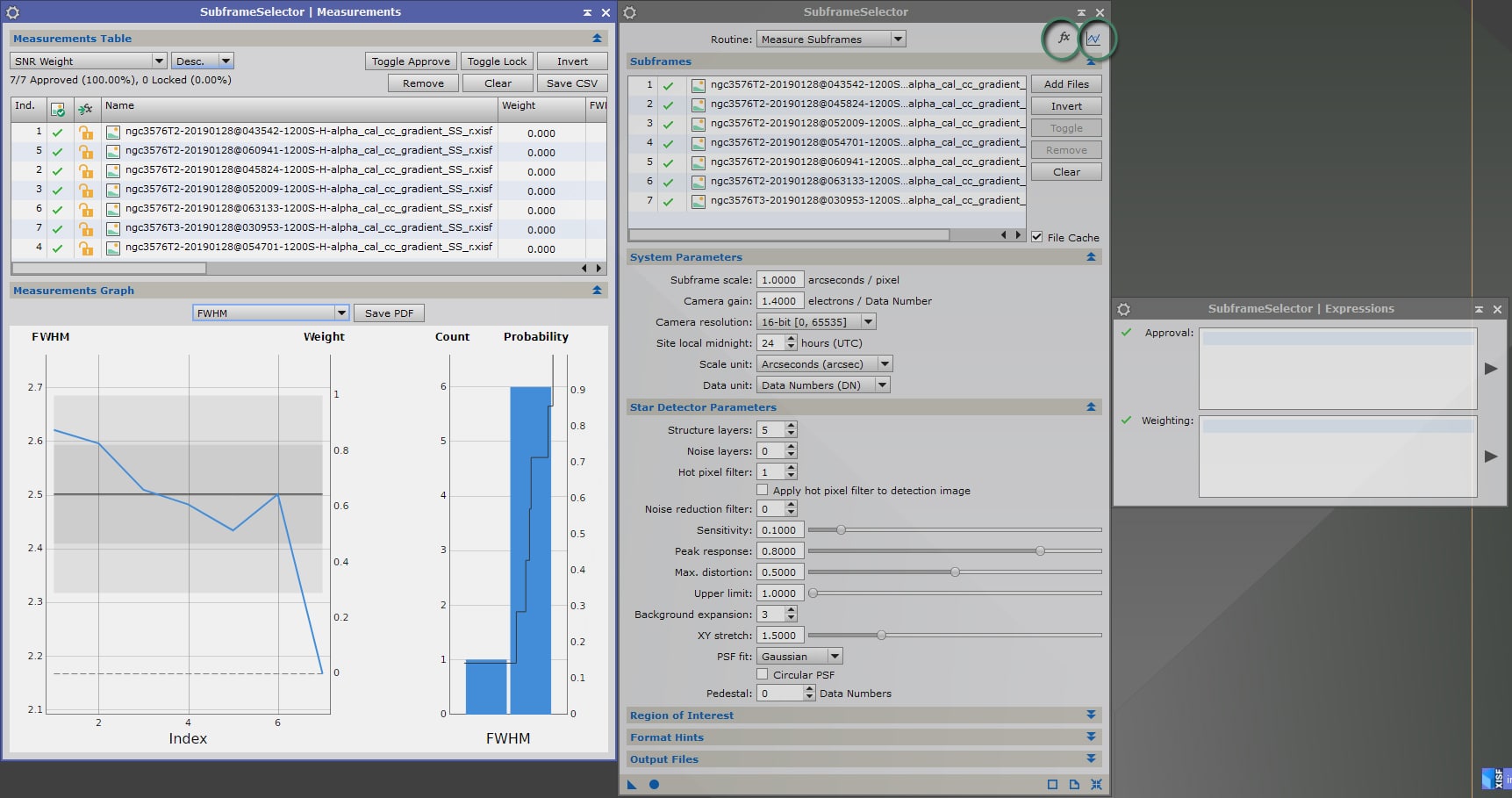
Dans le volet « Subframes », ajoutez toutes vos images Light dans leur dernière version en cliquant sur « Add Files ».
Dans la mesure où nous commençons par une phase de mesure des images, veillez à ce que la « routine » utilisée soit bien configurée sur « Measure Subframes » tout en haut de la fenêtre de process (comme surligné dans l’exemple ci-contre).
Dans l’onglet « Star detector parameters », les deux options les plus importantes sont « Structure layers » et « Noise layers ». Les paramètres par défaut (5/0) donnent le plus souvent de bons résultats.
Dans certains cas, il peut cependant être nécessaire d’exclure des mesures les étoiles les plus brillantes, qui peuvent induire des erreurs dans les mesures en raison de halos. Dans ce cas, vous pouvez abaisser le paramètre « Structure layers » à 4.
De la même manière, les étoiles les plus faibles risquent de ne pas présenter un rapport signal sur bruit suffisant pour que leur mesure soit pertinente dans les mesures. Vous pouvez remonter le paramètre « Noise Layers » à 1, voire 2 en cas d’image fortement bruitée ou avec une faible détectivité dans le fond de ciel.
Attention cependant à ne pas être trop restrictif dans ces paramètres, car vous risquez de trop limiter l’échantillonnage d’étoiles utilisées pour les mesures, et donc de fausser également ces dernières. Par exemple, avec « Structure layers » à 4 et « Noise Layers » à 2, vous ne prenez en compte que les structures des layers 3 et 4. Cela reste acceptable, mais veillez à ne pas réaliser les mesures sur un seul layer !
Si votre réglage ne permet pas de mesurer suffisamment d’étoiles (au moins quelques centaines), assouplissez ces paramètres ou augmentez légèrement le curseur « Sensibility ».
Cliquez sur « Apply global » pour lancer le process.
Une fois les calculs réalisés, 2 nouvelles fenêtres s’ouvrent : « Measurements » et « Expressions ». Vous pouvez fermer cette dernière qui ne nous servira pas ici.
Dans la fenêtre « Measurements », la partie supérieure consiste en la liste des images avec les différentes mesures réalisées, tandis que la partie inférieure représente sous forme de graphique les résultats des différentes images pour un critère déterminé.
Les critères les plus importants pour apprécier la qualité d’une image sont la FWHM (finesse des étoiles), « Noise » (le bruit) ou SNR Weight (inverse de la mesure du bruit : le poids attribué à chaque image est inversement proportionnelle à la quantité de bruit), et « Eccentricity » (excentricité des étoiles, la valeur étant d’autant plus élevée que les étoiles sont allongées et non ponctuelles).

Sélection de l’image de référence pour l’alignement
A ce stade, et pour faire simple, nous avons seulement besoin d’identifier l’image présentant la meilleure finesse. C’est donc le critère FWHM qui va seul nous intéresser.
Réglez les critères comme dans l’exemple ci-dessous, en retenant le paramètre FWHM ; soit dans le tableau en mode de présentation « ascendant », soit sur le graphique.
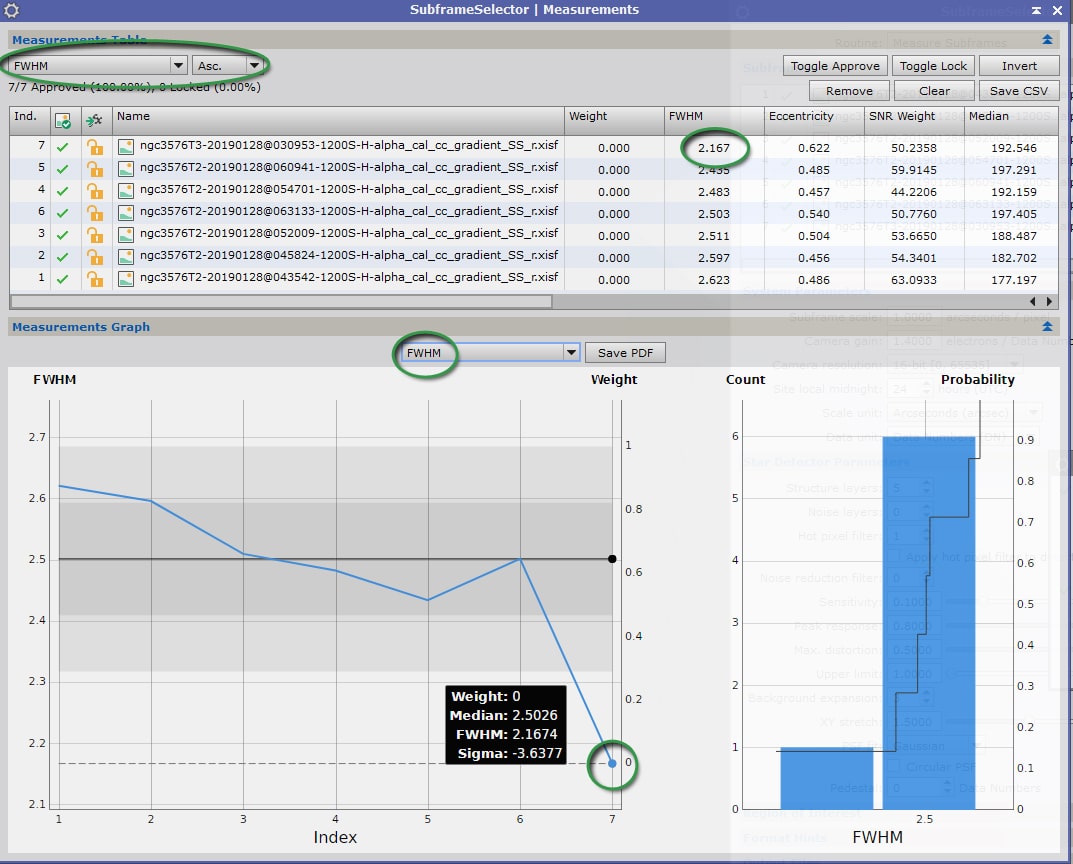
L‘image n°7 est nettement devant les autres sur ce seul critère…
Ici une image se détache nettement des autres en terme de finesse (la n°7). Elle constituera une excellente image de référence pour l’alignement des images, car présentant a priori la meilleure résolution… mais vérifions quand même un autre paramètre avant de la retenir : l’excentricité.
En effet, pour définir l’image de référence pour l’alignement, mieux vaut que cette dernière présente des étoiles bien rondes, et non étirées !
Paramétrons cette fois pour visualiser les résultats avec « Eccentricity » :
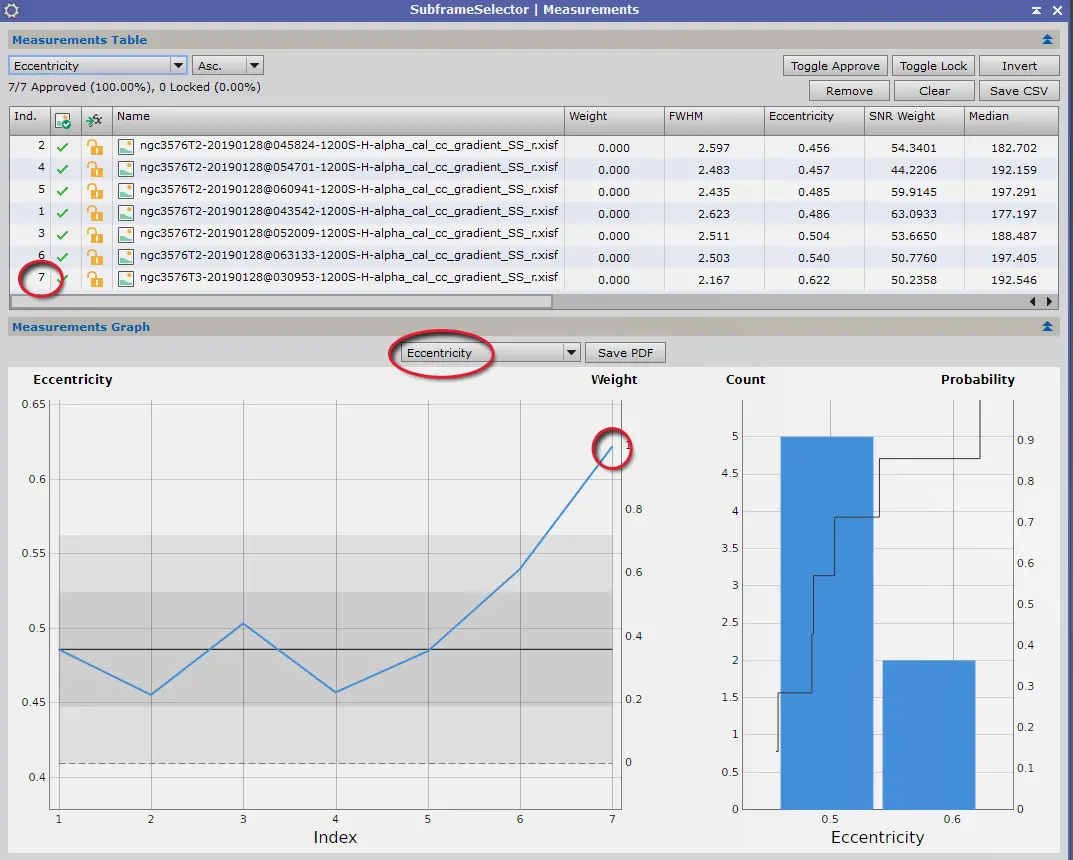
Cette fois, l’image n°7 présente le moins bon résultat ! Il n’est donc pas possible de la retenir comme image de référence pour l’alignement.
Pour sélectionner l’image de référence, nous allons donc devoir trouver l’image présentant le meilleur compromis en terme de FWHM et d’excentricité.
Étudiez l’excentricité des images par ordre croissant de FWHM pour trouver le meilleur compromis.
Dans notre exemple, cette image est la n°4, qui combine des résultats supérieurs à la moyenne pour ces deux critères.
Vérifiez juste en complément que cette image contient un nombre d’étoiles suffisant et pas extrêmement inférieur aux autres images.
Notez le nom de cette image comme image de référence pour l’alignement. Pour ce tutoriel, appelons-là « Image référence-alignement« .

Optimisation en vue de l’empilement : 2 méthodes
A ce stade, vous avez le choix entre 2 méthodes différentes pour optimiser l’empilement à venir des Lights : la plus simple (Piste Blanche) consiste à déterminer une image de référence ; la plus complexe (Piste Bleue) consiste à attribuer à chaque image un coefficient de pondération.
La méthode la plus simple pour optimiser ensuite l’empilement des Lights est de déterminer une image de référence présentant le meilleur rapport signal sur bruit.
Nous paramétrons donc la visualisation des résultats pour afficher les valeurs de « SNR Weight ».
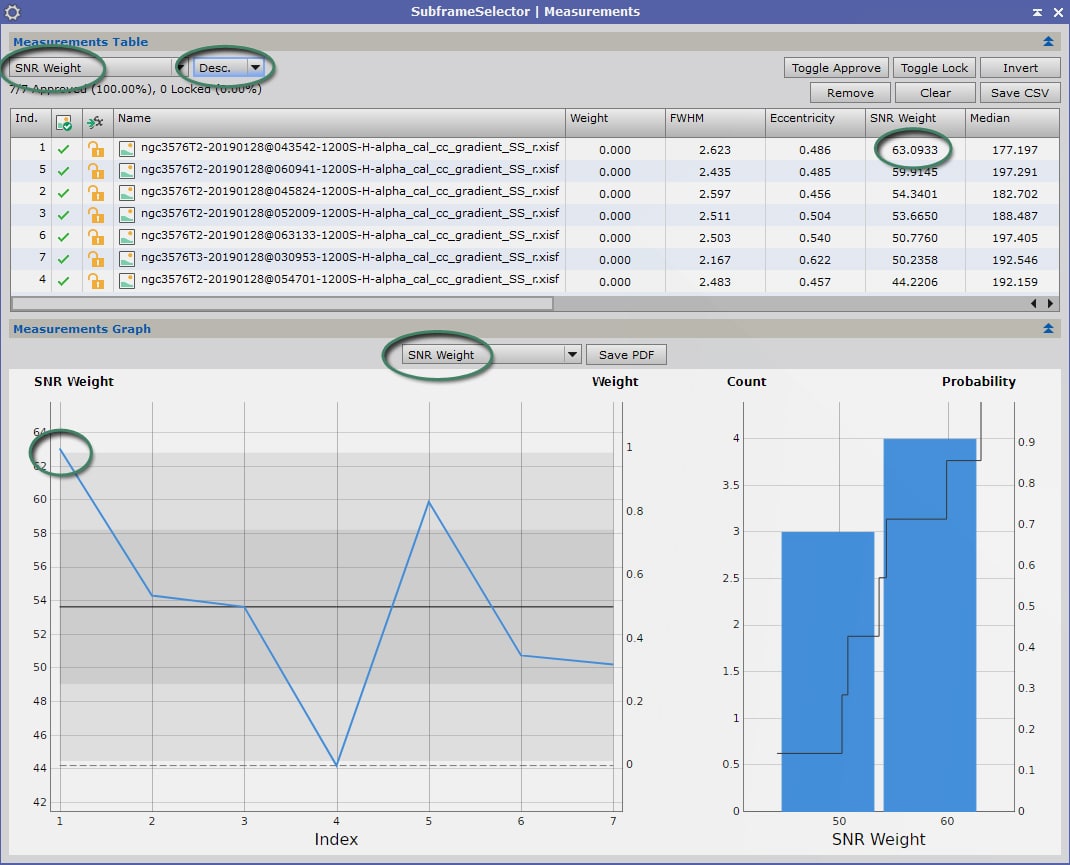
L’image se détachant assez nettement ici est la n°1. Ce sera notre image de référence pour l’empilement des images Light.
Notez le nom de votre image de référence pour l’empilement. Pour ce tutoriel, appelons-là « Image Référence-Empilement« .
Vous pouvez désormais poursuivre le traitement à l’étape suivante.
Choix de la formule et des coefficients de pondération
Contrairement à ce qui a été exposé dans la « Piste Blanche » ci-dessus, nous n’allons pas chercher à déterminer une image de référence mais à attribuer un coefficient de pondération à chacune des images Lights.
Le process Subframe Selector est parfois utilisé à cette étape pour éliminer certaines images, jugées insuffisamment qualitatives pour être intégrées à l’image finale lors de l’empilement. C’est le cas par exemple des images présentant une déviance trop forte par rapport à l’écart-type moyen de l’ensemble des images, que ce soit sur les critères de FWHM, de bruit, d’excentricité, etc.
Pourtant, j’ai eu l’occasion de vérifier, à de multiples reprises, qu’écarter ainsi des images globalement inférieures mais ne présentant pas de défauts rédhibitoires (défauts de suivi, de mise au point, etc.) entraîne une perte de qualité dans l’image finale, en particulier dans le rapport signal sur bruit.
Par exemple, pour mes images de M63 et M101, une sélection pure et simple des images conduisait à écarter entre 30% et 50% des brutes, avec à la clé une image moins riche en signal : un résultat particulièrement marqué en comparant les 2 versions d’empilement !
Chaque image, même de qualité moindre, peut en effet contribuer à améliorer le résultat final… à condition de lui attribuer une proportion dans l’image finale à la hauteur de sa qualité : une image de grande qualité doit contribuer fortement au résultat final, une image de moindre qualité doit contribuer plus faiblement, plutôt qu’être simplement écartée.
Autrement dit, mieux vaut intégrer toutes ses images en leur attribuant un coefficient de pondération adéquat en rapport avec leur qualité et sur la base des mesures de différents critères.
Les critères principaux sont les mêmes que ceux énoncés précédemment : FWHM, SRNWeight, Eccentricity. Il faut donc intégrer ces 3 paramètres au sein d’une seule et même formule qui augmente la pondération pour les images dont ces critères sont supérieurs à la moyenne de l’ensemble des images.
Ici, chacun est libre de développer sa formule personnelle, qui permettra d’attribuer un coefficient aux images selon ses critères personnels, les performances de son matériel, la qualité du ciel du lieu d’observation, etc.
Ainsi, un photographe disposant d’un observatoire à poste fixe et disposant d’un ciel à la qualité relativement équilibrée et à la turbulence stable pourra choisir de donner moins d’importance à la FWHM (qui serait relativement constante en moyenne sur une session) et privilégier le rapport signal sur bruit.
Une solution d’équilibre reste cependant d’attribuer un poids à peu près équivalent à ces 3 critères.
Depuis la version 1.8.6 de Pixinsight et le passage de Subframe Selector de script en process, il est possible d’intégrer dans les formules « Expressions » les variables renvoyant aux valeurs « min » et « max » de chacun des paramètres de mesure. Il est donc désormais possible de développer une formule qui soit utilisable à chaque traitement sans y apporter de modifications.
FWHM et Eccentricity
Plus les facteurs FWHM et Eccentricity sont faibles, meilleure est l’image : il faut donc définir un coefficient inversement proportionnel à la valeur de ces paramètres.
Pour FHWM, la solution la plus triviale est donc d’attribuer à ce facteur un coefficient du type :
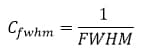
Pour l’excentricité, celle-ci est comprise en 0 (étoiles parfaitement rondes) et 1 (étoiles très allongées). Le coefficient de pondération peut donc s’établir simplement sous la forme suivante :
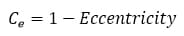
Il est cependant possible d’affiner un peu ces coefficients en prenant en compte les valeurs médianes de ces deux paramètres pour la série d’images :

On voit qu’une image présentant une valeur égale à la médiane des valeurs de la série ne sera pas affectée par ces coefficients et obtiendra un coefficient de 1. Les images moins bonnes que la médiane seront pénalisées (coefficient < 1) et les meilleurs images obtiendront un bonus (coefficient > 1).
SNR Weight
Contrairement aux deux paramètres précédents, plus le facteur SNR Weight est élevé plus l’image est de qualité. Il faut donc ici attribuer un coefficient de pondération qui augmente proportionnellement avec la valeur de ce paramètre.
Ici encore, une solution trivial est simplement d’attribuer comme coefficient pondérateur le facteur SNR Weight lui-même :
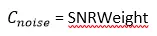
Pour affiner par rapport à la valeur médiane, le coefficient peut être transformé sous la forme suivante :
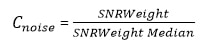
Dans ce cas, une image présentant la valeur médiane de la série ne sera pas affectée par ce coefficient (valeur 1), tandis que les images inférieures à la médiane seront pénalisées (coefficient < 1) et les meilleures se verront accordé un « bonus » (coefficient > 1).
La formule de pondération
En utilisant les différents coefficients de pondération établis ci-dessus, on peut établir plusieurs formules de pondération.
La plus simple découle de la combinaison des facteurs triviaux :
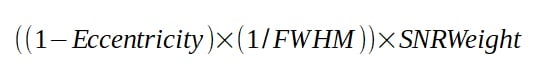
Dans notre exemple, on obtient avec cette formule les résultats suivants :
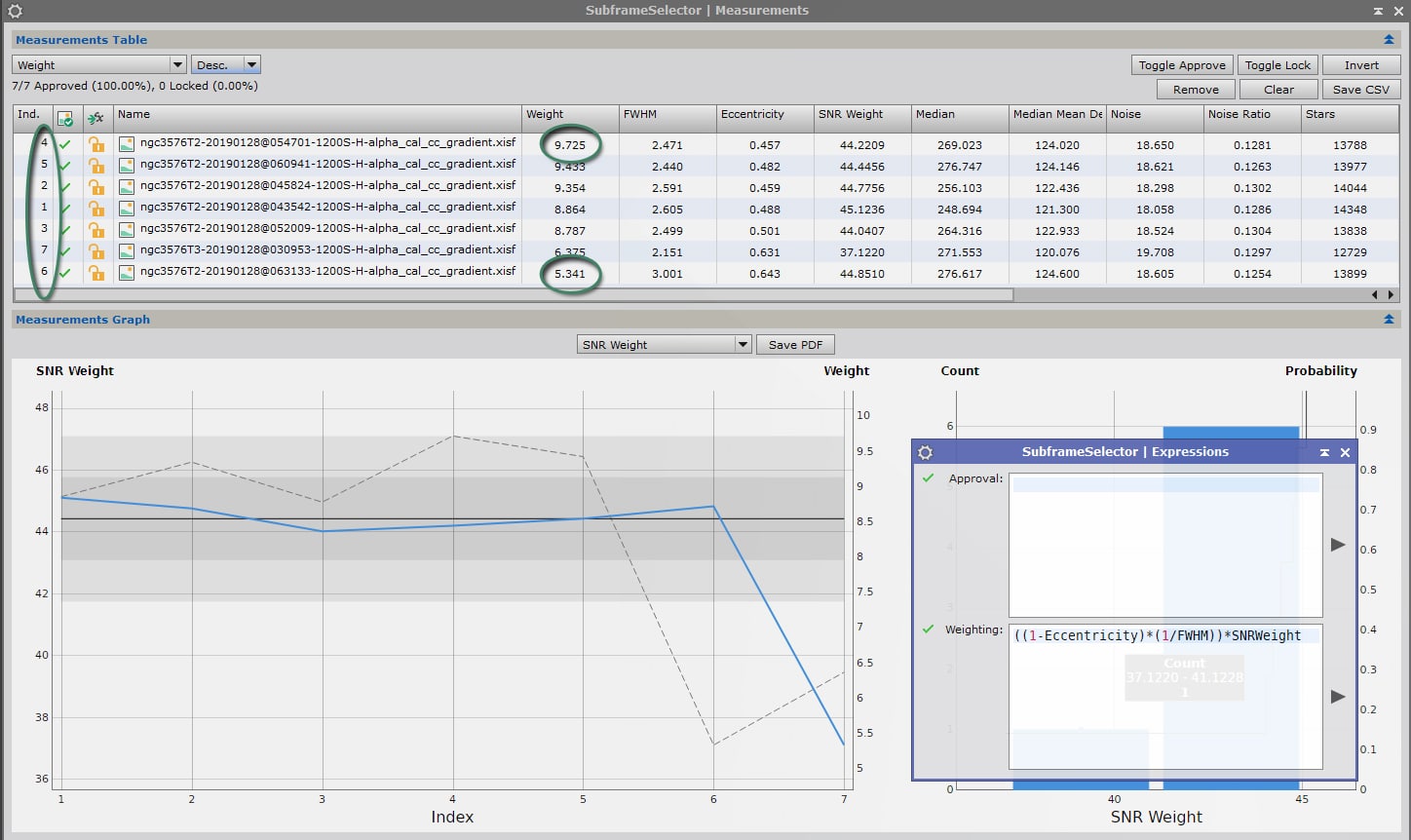
On constate que la pondération suit pour l’essentiel les valeurs de SNRWeight, mais les images présentant les plus grands défauts en matière de FWHM et d’excentricité sont pénalisées. L’image n°7, qui présentait la meilleure FWHM mais un rapport signal sur bruit en retrait, voit ainsi son coefficient de pondération quelque peu rattrapé. L’image n°6, qui présentait la pire FWHM, est quant à elle fortement pénalisée.
Utilisons maintenant la formule tenant compte des meilleures valeurs de la série d’images :
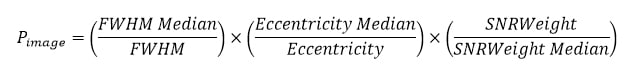
On obtient avec cette formule les résultats suivants :
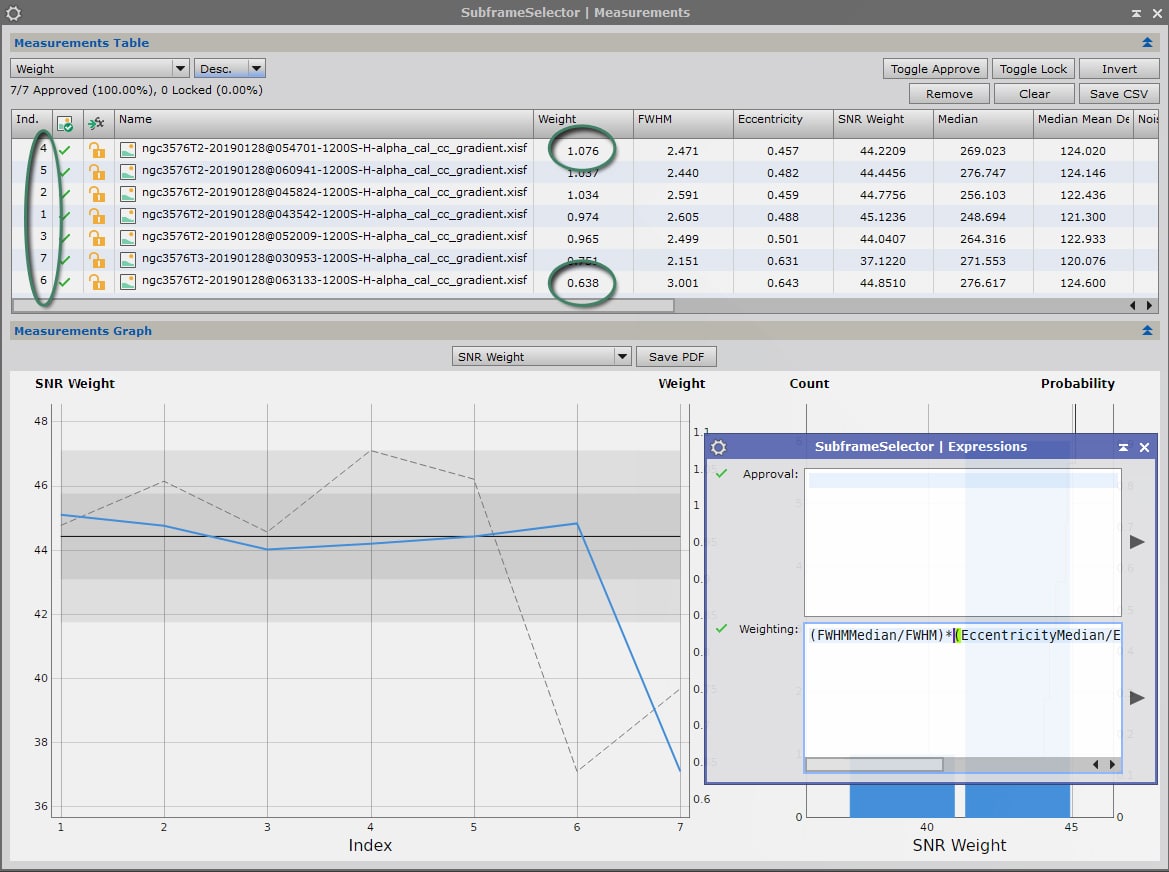
Les résultats obtenus sont similaires à ceux obtenus avec la formule précédente, mais la différence de pondération est moindre puisque la meilleure image se voit attribué un coefficient 1,68 fois supérieur à la moins bonne image, contre 1,82 avec la formule triviale.
A ce stade, nous avons attribué à ces 3 paramètres des importances égales. Toutefois, ceux-ci ne sont pas systématiquement équivalents selon les objets photographiés et le traitement envisagé ensuite. Ainsi, pour une photographie de nébuleuse diffuse, on sera tenté de favoriser le rapport signal sur bruit par rapport à la FWHM et l’excentricité ; alors que pour une nébuleuse planétaire présentant de petits détails, ce sont au contraire ces 2 derniers paramètres qui devront être valorisés.
Pour un usage « classique » en ciel profond, nous allons recommander la formule suivante, qui part du principe : SNR > FWHM = Excentricité, en portant la part de SNR au carré :
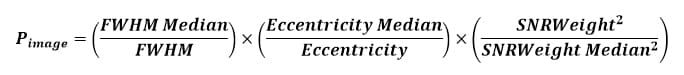
Les résultats obtenus avec cette formule sont les suivants :
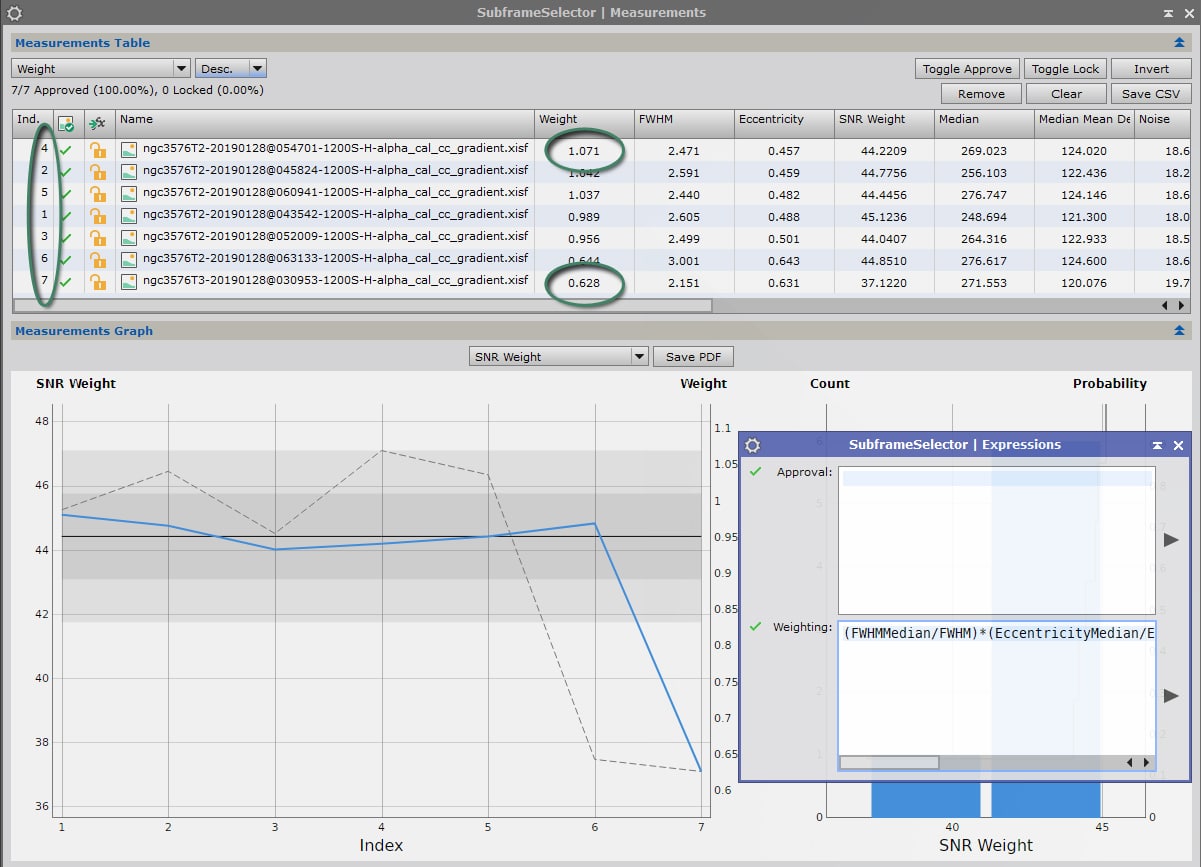
Cette formule de pondération, qui accorde une plus grande importance au rapport signal sur bruit, vient modifier le classement des images : les bons résultats des images présentant une FWHM et une excentricité correctes ne rattrape pas autant leur déficit en SNR.
Si vous souhaitez privilégier davantage la FWHM au détriment du signal sur bruit pour des usages particuliers, il suffit de porter au carré non pas le coefficient de pondération de SNRWeight, mais celle de FWHM :
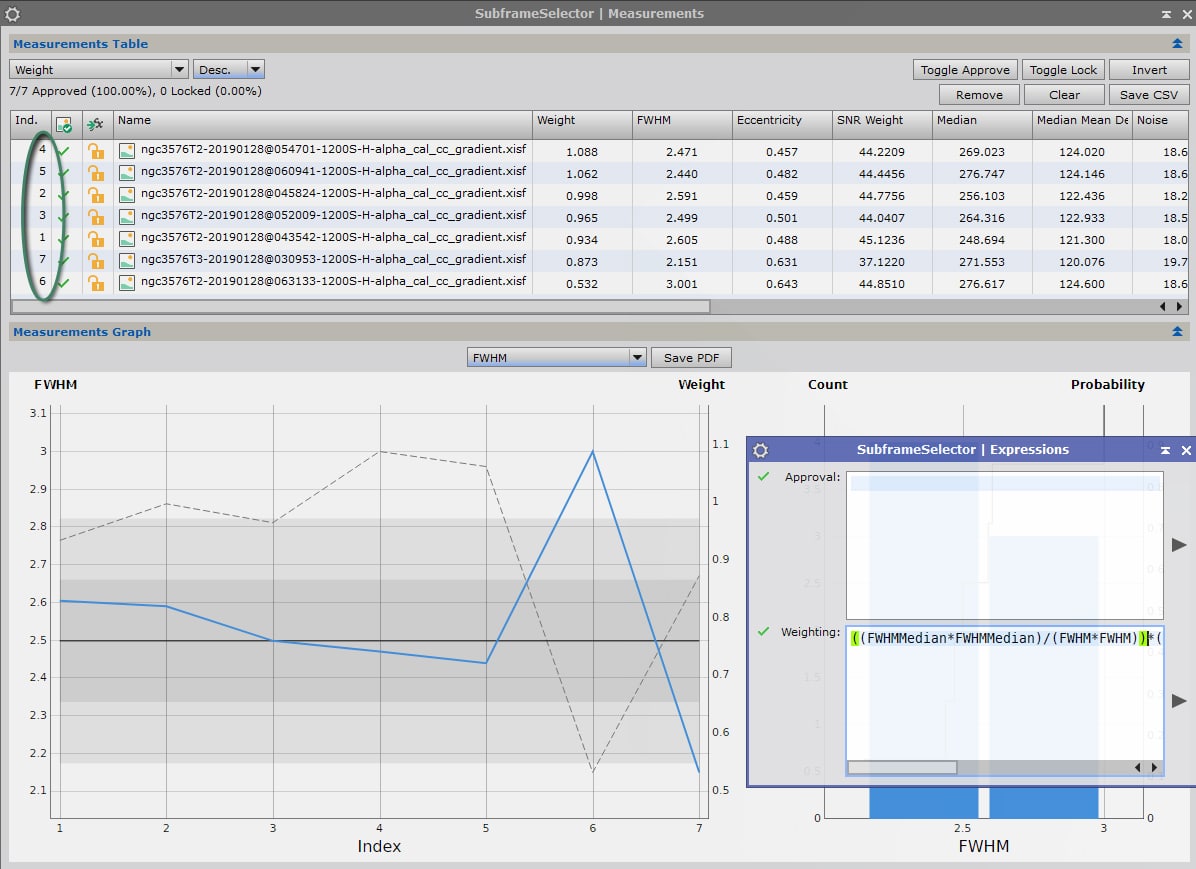
Vous l’avez compris, rien ne vous empêche de personnaliser cette formule de base en fonction de vos besoins ; voire de créer votre propre formule personnalisée !
Vous trouverez sur Internet de nombreux exemples de formules de pondération, plus ou moins complexes. Mentionnons par exemple la formule retenue par LightVortex, inspirée par celle de David Ault :
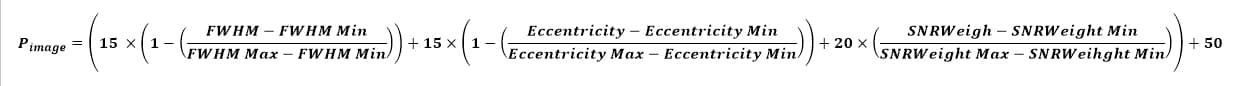
Dans cette formule, chacun des termes FWHM, Eccentricity et SNRWeight est compris entre 0 et 1. Des facteurs de pondération sont ensuite appliqués pour chacun des termes (respectivement 15, 15 et 20). Une valeur constante de 50 est enfin ajoutée, nivelant ainsi les écarts globaux et conduisant à ce que toutes les images présentent un coefficient de pondération unitaire compris entre 50 (très mauvaise image) et 100 (image très bonne).
L’application de cette formule sur les mêmes images que précédemment donne les résultats suivants :
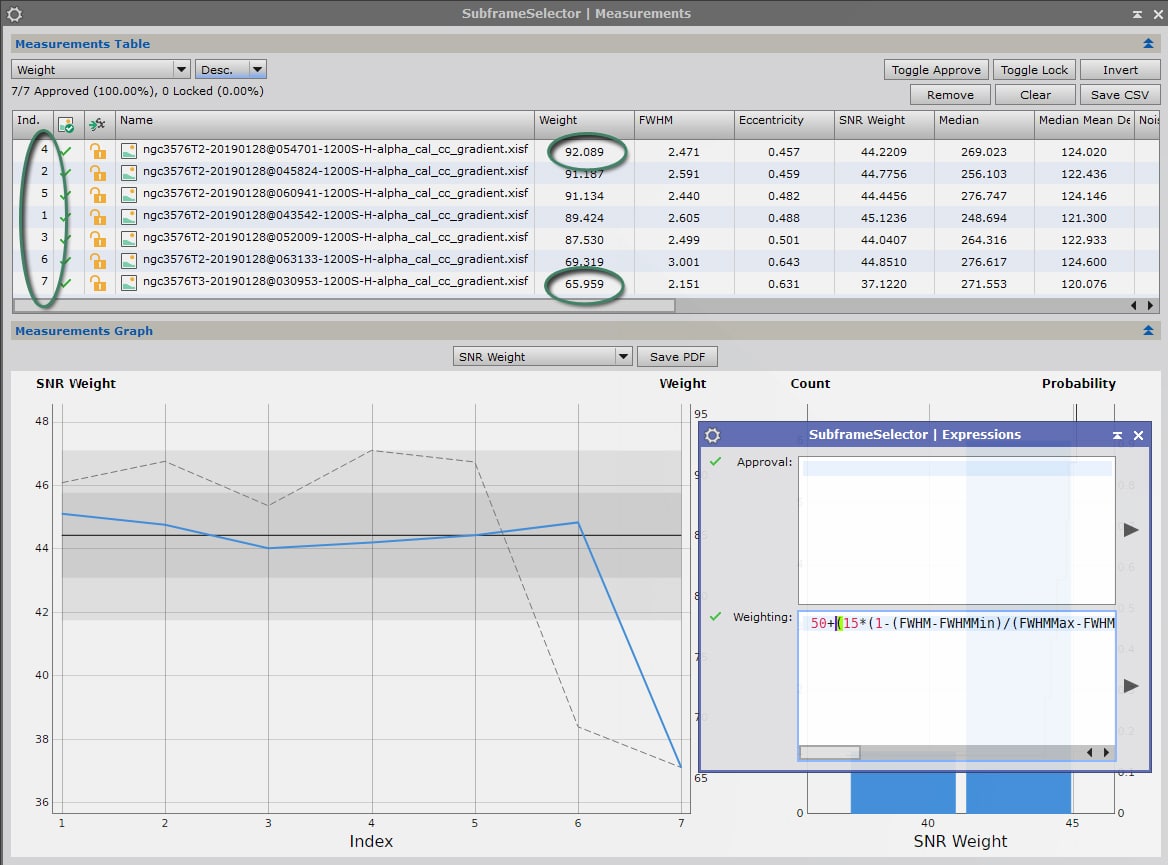
Notez que le classement des images est le même que celui obtenu avec la formule « médiane – SNR renforcé », mais le rapport entre les images est moins accentué (1,40x au lieu de 1,70x).
A titre personnel, je préfère conserver une distinction plus marquée entre les bonnes et les mauvaises images, mais encore une fois vous êtes tout à fait libre de personnaliser la formule selon vos besoins !
Notez le nom de l’image à laquelle est attribuée le plus fort coefficient de pondération (appelons-là « Image Référence-Pondération« ).
Enregistrement de la pondération des images
Une fois les coefficients et la formule définis et vérifiés, il faut intégrer les coefficients à chacune des images.
Pour ce faire, revenez à la fenêtre principale du process et sélectionnez cette fois la routine « Output Subframes ».
Indiquez un mot-clé (« Keyword ») qui sera utilisé lors de l’empilement des images. Dans notre exemple, nous utilisons le mot « COEF ».
Ce mot-clé et sa valeur correspondante seront intégrés dans le « Fits header » de chaque image à l’issue du process.
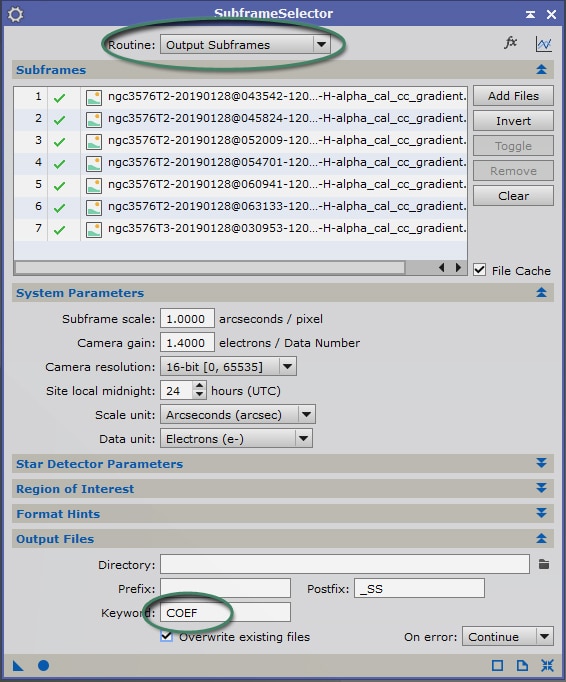
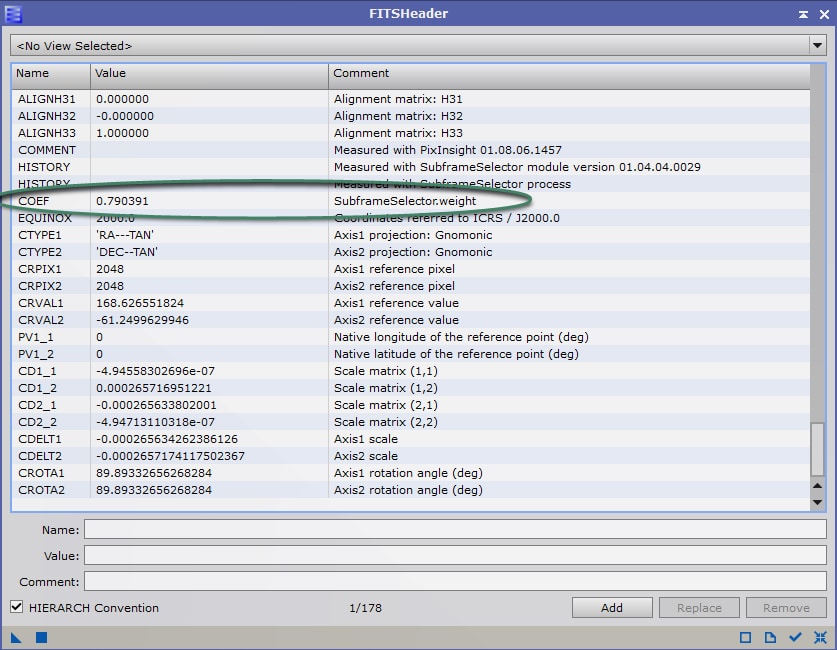
Si besoin, précisez également le « postfix » des images traitées ainsi que le fichier de destination des images pondérées.
Lancez ensuite le process.
Comparaison des résultats obtenus avec les 2 méthodes
Avant de conclure cette partie (et pour justifier les options recommandées…), voici une comparaison rapide entre les images d’empilement obtenues avec chacune des méthodes présentées ici : d’une part :
Image 1 : empilement de 100% des images pondérées avec la méthode expliquée ci-dessus (avec la formule « médiane SNR optimisé ») un empilement réalisé sur une sélection des meilleures brutes (70%) après alignement avec Image Référence-alignement,
Image 2 : empilement avec Image Référence-Empilement mais sans pondération.
Ici encore, nous utilisons le process SubframeSelector pour mesurer les résultats :
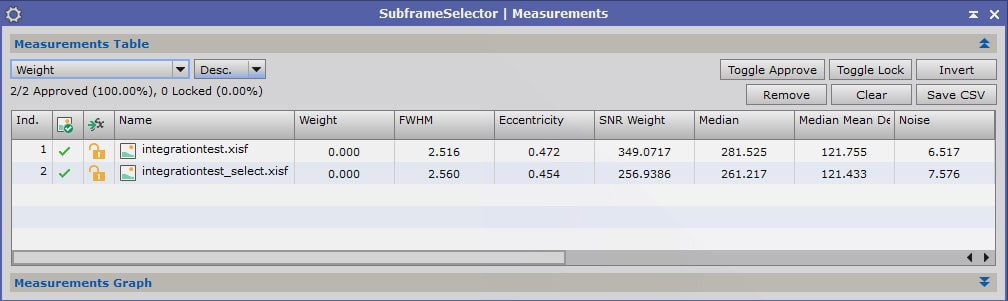
Le résultat est clairement en faveur de la méthode d’empilement globale avec pondération, sur tous les paramètres importants (bruit, FWHM…) et en particulier le SNRWeight.
8. Alignement des images Light
A ce stade, toutes nos images ont été prétraitées individuellement et nous disposons d’une image de référence en terme de finesse d’étoiles.
Il est donc possible de procéder à l’alignement de l’ensemble des images. Cet alignement peut être réalisé de manière très simple avec le process StarAlignement.
Lancez ce process et appuyez en cas de doute sur la configuration sur l’icône « Reset » en bas à droite de la fenêtre ; afin de restaurer les paramètres par défaut.
Dans « Target Images », ajoutez l’ensemble de vos fichiers Light.
Dans « Reference Image », indiquez votre Light de référence ; dans notre exemple Image Référence-alignement.
Piste Bleue : Si vous souhaitez pouvoir obtenir une image en mode « drizzle » au final, n’oubliez pas de cocher l’option « Generate drizzle files » (notez qu’à ce stade aucune image « drizzle » ne sera générée, mais uniquement des fichiers « .xdrz » qui seront utilisés plus tard pour la création de cette image).
Précisez ensuite si besoin les postfix des images alignées en fin de process, ainsi que le répertoire de destination. Si vous ne l’avez pas déjà fait plus tôt, il est recommandé de réunir toutes vos images alignées au sein d’un seul dossier pour chacun des filtres.
Si les images à aligner ont toutes été réalisées avec la même optique, il n’est pas utile de cocher l’option « Distortion correction ».
Les paramètres de l’onglet « Star Detection » permettent d’affiner au besoin la détectivité des étoiles sur les images.
Les paramètres « Star Matching » permettent quant à eux de définir les critères de l’algorithme de correspondance des étoiles entre les images.
Signalons d’emblée que les paramètres par défaut de « Star Detection » et « Star Matching » donnent, dans la très grande majorité des cas, d’excellents résultats et ce, avec une grande rapidité de traitement ! Comptez environ 5 secondes par image avec un PC de puissance courante ; 7 secondes si vous activez l’option « Distortion Correction« . Attention cependant, la durée de traitement augmente rapidement avec les paramètres de tolérance et le nombre d’itérations : plus de 5 minutes par image pour tolérance = 8 et 4000 itérations RANSAC !
Aussi, ne les modifiez que si vous rencontrez des difficultés pour aligner tout ou partie des images avec les paramètres par défaut.
En cas d’échec du process pour cause d’un nombre insuffisant d’étoiles (message « Error : No Stars Found » dans la console), vous pouvez faire un nouvel essai en diminuant le paramètre « Log(sensitivity)« . En cas de nouvel échec, augmentez légèrement les paramètres « Peak response » et « Maximum distortion« .
Surveillez à chaque essai dans la console le nombre d’étoiles détectées dans l’image, afin d’identifier le paramètre influençant le plus sur la détection pour votre série d’images.
En cas d’échec en raison de l’incapacité du process de procéder à des correspondances d’étoiles malgré un grand nombre d’étoiles détectées dans les images (message « Error: Unable to find an initial set of putative star pair matches » dans la console), il convient de modifier les paramètres de « Star Matching ». Notez que Pixinsight a besoin d’au moins 6 correspondances d’étoiles pour procéder à l’alignement des images.
Pour ce faire, commencez par augmenter « RANSAC tolerance » à 4 et le nombre d’itérations du process « RANSAC iterations » à 4000. En cas de nouvel échec, augmentez le paramètre « RANSAC tolerance » et éventuellement le nombre d’itérations.
Si malgré tout vous ne parvenez pas à aligner automatiquement vos images, même avec les paramètres de « Star Detection » les plus tolérants et avec les paramètres « Star Matching » les plus itératifs, il se peut en de rares occasions que le souci vienne de vos images : soit que celles ci ne contiennent réellement qu’un nombre très réduit d’étoiles, soit que les images soit excessivement décalées les unes par rapport aux autres, soit enfin qu’une modification de géométrie ait été réalisée sur l’image de référence (inversion miroir, symétrie, etc.).
Dans certains cas, un trop grand nombre d’étoiles peut également se révéler contre-productif et rendre difficile la recherche des correspondances. Dans ce cas, essayez de rendre plus restrictifs les paramètres de « Star Detection ».
Essayez également de modifier l’image de référence en cas d’échecs répétés.
Pour les cas désespérés où aucun alignement ne peut être réalisé, il faudra envisager un alignement « manuel » (mais largement assisté…) avec le process « DynamicAlignement« .
Pas de grosse difficulté en vue sur cette « Piste Bleue » : paramétrez le process de la même manière que pour la « Piste Blanche » (activez notamment l’option « Generate drizzle files« ) et activez l’option « Distortion correction » dans la fenêtre StarAlignement.
Cochez l’option « Undistorted reference » ; nous allons considérer ici que notre meilleur image de référence n’est pas affectée par la distorsion.
Les options par défaut donnent généralement de bons résultats. En cas d’échecs de la correction de distorsion, augmentez le nombre d’itérations par « Distortion iterations« .
En cas d’échecs liés aux autres paramètres d’alignement, procédez aux ajustements comme expliqués dans la « Piste Blanche » ci-dessus.
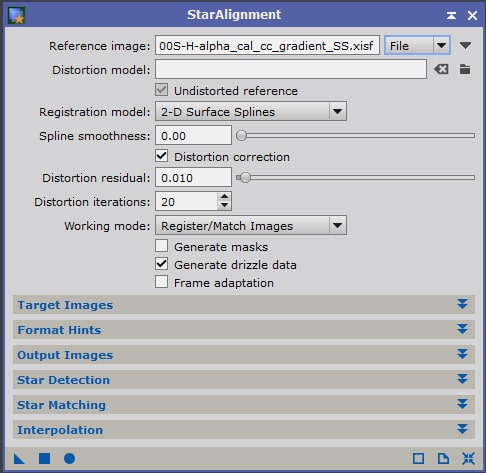
Remarque : Dans la mesure où nous effectuons la correction de la distorsion par rapport à une image de référence que nous considérons comme n’étant pas affectée par la distorsion, la correction réalisée ci-dessus n’est que « relative ».
Une correction de distorsion « absolue » peut être réalisée avec une méthode alternative plus complexe consistant à générer une carte d’étoiles synthétique « idéale » et d’utiliser cette dernière comme référence pour l’alignement et la correction de la distorsion.
Cependant, cette solution ne se justifie réellement que dans certains cas particuliers : pour des optiques fortement affectées par la distorsion, en cas d’utilisation d’optiques différentes pour une même image, la réalisation de mosaïques complexes avec une multitude de tuiles, ou encore des images de très grands champs.
Pour les images « classiques », cette opération complexe n’apporte pas un gain qualitatif significatif ; aussi nous ne l’aborderons pas ici. Cette méthode sera décrite lors d’un futur tutoriel consacré à la réalisation des mosaïques.
Si vous souhaitez aligner des images de taille différente (réalisées avec un autre setup, une autre caméra, une optique différente, etc.), il est nécessaire de cocher dans l’onglet « Star Matching » l’option complémentaire « Use scale differences ».

Le paramètre « Scale tolerance » permet « d’aider » le process à retrouver plus rapidement des correspondances entre les images. Pour des images de taille très différentes (par exemple 50/100), ou si vous n’avez pas déterminé cet écart avec précision, réglez ce paramètre sur la valeur maximum (1).
Attention à la configuration de l’image de référence : les images en sortie seront ajustées en taille par rapport à celle-ci. Par exemple, si votre image de référence est une « petite » image, les « grandes » images seront réduites en taille à l’issue de ce process.
9. Local Normalization
A quoi sert LocalNormalization (et faut-il réellement l’utiliser…) ?
Le process Local Normalization est une innovation apportée par la version 1.8.5 de Pixinsight.
L’objectif est d’appliquer un algorithme de « normalisation » de l’histogramme de chaque image, de manière localisée, sur la base de l’histogramme d’une image de référence disposant du meilleur rapport signal sur bruit (et du fond de ciel le plus propre possible, sans traces de satellites par exemple). L’histogramme de l’image cible va être redistribué pour être statistiquement cohérent (compatible) avec l’histogramme de l’image de référence.
La correction va ainsi être appliquée de manière localisée, par zones dont la taille unitaire est définie par la valeur « Scale » (128 pixels par défaut).
Correctement configuré, ce process permet non seulement de rendre les images plus cohérentes entre elles (utile avant d’effectuer des opérations de réjection dans le cadre de l’empilement à venir), d’améliorer l’homogénéité du fond de ciel, ou encore d’obtenir des zones de transition plus subtiles. Il est important de réaliser cette opération après le retrait des gradients, pour disposer d’une image de référence la plus « propre » possible.
Si vos images sont globalement bonnes, les modifications demeureront subtiles… En revanche, sur certaines images présentant de gros défauts de halos, de reflets, d’inhomogénéité de fond de ciel, ou d’autres défauts de grande structure, l’amélioration peut être tout à fait spectaculaire. L’exemple ci-dessous, mis en ligne par un utilisateur sur le forum de Pixinsight, en fournit une illustration flagrante !
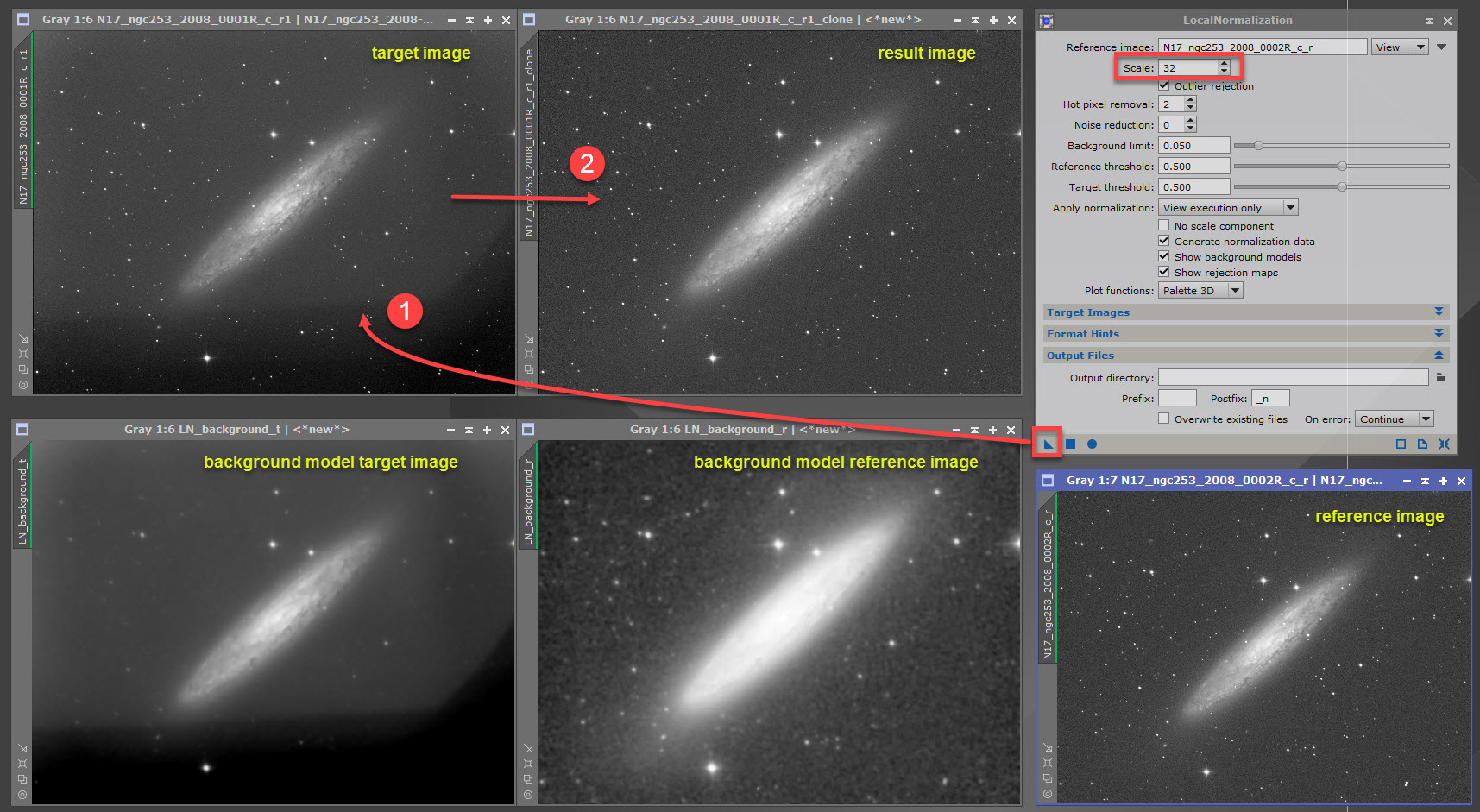
(c) Herbert W. – Source : Forum Pixinsight.
Un autre exemple, réalisé sur l’une de mes images particulièrement affectée par différents défauts : flats, problèmes d’alignements entre deux séries de poses, et homogénéité du fond de ciel en raison de légers passages de voiles nuageux pendant les acquisitions. Le traitement LocalNormalization a été réalisé avant empilement sur toutes les images brutes en prenant comme référence la meilleure image Light brute dépourvue de l’ensemble de ces défauts :
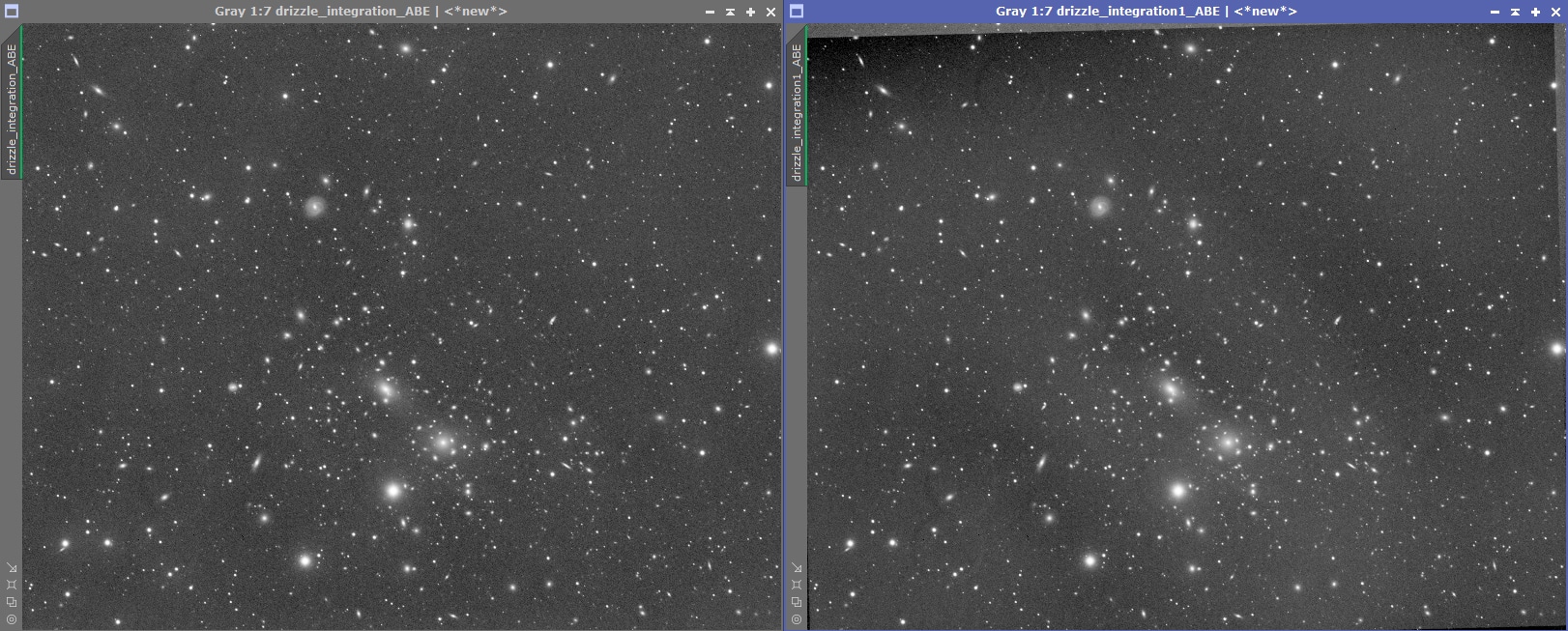
Naturellement, le process ne fait pas de miracles, et ne fait pas disparaître les voiles nuageux comme par magie… mais notez cependant que les défauts sont réellement atténués : plus besoin de croper l’image, et le fond de ciel est bien plus uniforme. L’image traitée de manière classique serai quasiment impossible à traiter correctement, alors que l’image de gauche est traitable, avec quelques limitations qui pourront être corrigées lors des étapes finales du traitement.
On visualise bien ici le fonctionnement et l’intérêt de LocalNormalization : le process va modéliser le fond de ciel d’une image de référence et modifier de manière cohérente celui de l’image cible. Les paramètres doivent cependant être finement ajustés (en particulier sur la valeur de « Scale ») dans un tel cas d’image « extrême »…
Précision importante : ce process ne donne des résultats que sur de grandes structures (au moins plusieurs dizaines ou centaines de pixels adjacents) : inutile de l’utiliser pour corriger des défauts de petite taille ou encore des marques résiduelles de flats (« donuts » de poussières très sombre, par exemple, qui certes peuvent manifester sur des zones larges, mais dont la limite avec le fond de ciel n’occupe que quelques pixels adjacents…).
La limite basse de la valeur « Scale » est ainsi de 32 pixels ; et peut être portée à plusieurs centaines voire milliers pour des corrections portant sur de très grandes structures.
Sur des images classiques dépourvues de défauts importants, cette étape permet une légère optimisation des images avant l’empilement. Toutefois, compte-tenu de la complexité des réglages de ce process et du gain moyen espéré, il m’a semblé justifier de réserver cette étape à la « Piste Rouge », sur laquelle les moindres petits raffinements supplémentaires sont recherchés.
Si vous avez des doutes sur les modifications apportées, sur le gain qualitatif réel ou encore sur les meilleurs réglages, et que vos images sont globalement bonnes, vous pouvez sans regret sauter cette étape et passer directement à l’empilement de vos images…
Dernière précision afin d’éviter toute incompréhension : l’utilisation de Local Normalization ne génère aucune image spécifique, mais uniquement des fichiers « .xnml » comportant des informations sur les modifications à apporter à chacune des images Lights. Ces fichiers .xnml seront utilisés par la suite lors de la phase d’intégration des images Lights.
Utilisation du Process
Lancez le process LocalNormalization et ajoutez vos images Light dans l’onglet « Target Images ». Si besoin, modifiez le postfix des images traitées (par défaut « _n »).
Cochez l’option « Generate Normalization data » et ne modifiez pas les autres valeurs par défaut des curseurs (modélisation du fond de ciel) qui donneront de bons résultats dans la grande majorité des cas.
Avant de lancer le process sur les images indiquées, nous allons procéder aux réglages des paramètres en procédant à un essai sur une image cible.
Le paramètre « Scale », notamment, peut être conservé à sa valeur par défaut (128) pour un premier essai. Cochez également les options « Show Background models » et « Show rejection maps » afin de visualiser les zones de corrections et de réjection retenues par le process.
Ouvrez l’une des images de votre série à l’exclusion de votre image de référence Image Référénce-Pondération, si possible l’image avec le coefficient de pondération le moins élevé et donc le plus susceptible d’être affecté de défauts dans le fond de ciel ou d’un rapport signal sur bruit dégradé.
Créez un clone de cette image sur l’espace de travail afin de pouvoir visualiser les modifications apportées après traitement.
Appliquez le process LocalNormalization sur l’image cible ainsi ouverte en déplaçant l’icone NewInstance (triangle en bas de la fenêtre de process) sur celle-ci.
Une fois le process réalisé, l’image cible est directement corrigée et plusieurs images s’ouvrent dans la zone de travail principale. Celles qui vont nous intéresser sont les images LN_scale et LN_background_r. Les images de réjection
L’image LN_Background va permettre d’apprécier la modélisation globale du fond de ciel calculée par le process.
L’image LN_scale va quant à elle nous permettre d’apprécier le niveau de « détails » sur lequel les écarts d’homogénéité sont constatés et donc sur lequel les corrections sont apportées.
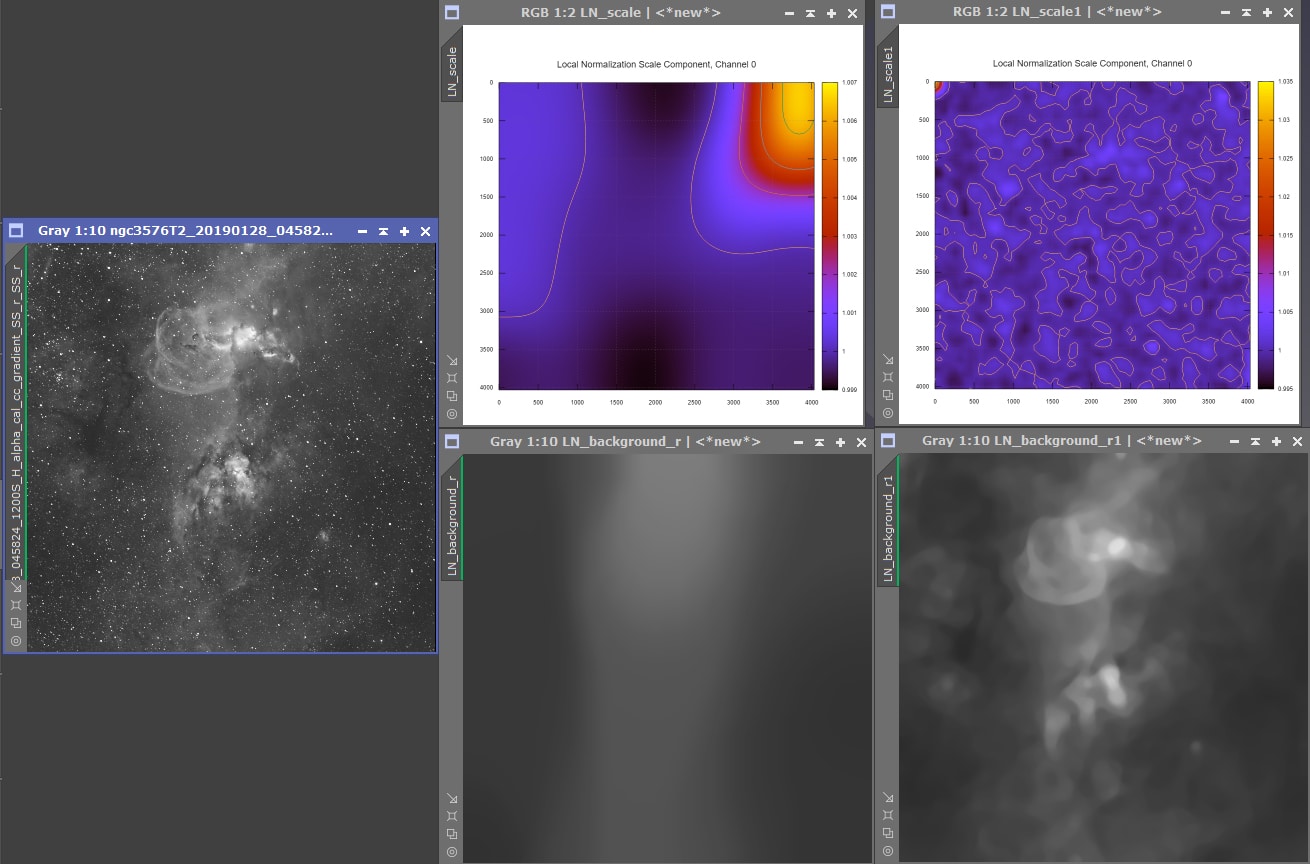
Sur cet exemple, la valeur 128 va permettre de corriger des inhomogénéités de plus petite échelle et plus pertinentes sur cette image.
Les résultats obtenus sont directement liés à la valeur du paramètre « Scale », de façon analogue aux « layers » utilisés habituellement pour l’application de différents process (retrait de bruit, par exemple) mais sur des structures de plus grande taille.
Sur l’exemple présenté (un peu « extrême » mais plus parlant pour illustrer le propos), on voit que la valeur Scale=1024 n’est pas adaptée car elle revient à modéliser une forme de « gradients » de trop grande ampleurs, qui n’est liée qu’à la répartition des objets brillants sur l’image : cela revient en quelque sorte à effectuer une correction de gradients mal modélisée car basée essentiellement sur les objets du ciel profond et non sur le fond de ciel… Ce n’est évidemment pas le but ici, dans la mesure où nous avons déjà procédé, avec une plus grande finesse, à un retrait de gradients en amont.
La valeur Scale=128 fournit en revanche des résultats bien plus intéressants : l’image LN_scale, à la différence de la version Scale=1024, montre des inhomogénéités indépendantes de l’objet principal dont la structure globale n’est pas identifiable.
Travailler sur des structures de cette dimension va donc nous permettre d’optimiser sensiblement nos images.
Il est bien sûr recommandé de procéder à quelques essais complémentaires pour déterminer la valeur de Scale optimale pour chaque série d’images. Sur cet exemple, nous pouvons également affiner cette valeur en réalisant des essais avec Scale=256 et Scale=64, afin d’apprécier plus précisément le niveau de structures. Au final, la valeur Scale=128 donnant les résultats les plus intéressants dans cet exemple, nous avons retenu ce réglage pour appliquer le process à l’ensemble des images Lights.
Procédez systématiquement à une comparaison entre l’image traitée et l’image de départ (clone créé précédemment) afin de vérifier la pertinence des corrections effectuées ainsi que leur ampleur. Avec des images de départ de bonne qualité, ces corrections doivent rester subtiles, avec une plus grande homogénéité du fond de ciel et éventuellement le renforcement de quelques zones plus sombres.

Une fois vos réglages déterminés et ces vérifications effectuées, lancez le process en cliquant sur l’icone « Apply global« .
Vous pouvez poursuivre le traitement en utilisant désormais vos images « Light_n« .
10. Empilement des images Light
Toutes les images Lights ont désormais été calibrées, alignées, optimisées… il ne reste plus qu’à les empiler ensemble pour obtenir une image disposant d’un signal sur bruit très amélioré.
Rappelons que le rapport signal sur bruit de l’image empilée sera amélioré, par rapport à une image unitaire, d’un facteur proportionnel à la racine carrée du nombre d’images empilées :
Dans ce tutoriel, nous avons retenu une approche consistant à éliminer le moins de brutes possibles (sauf celles affectées par des défauts rédhibitoires liés à la prise de vue : mauvais suivi, passages nuageux, mauvaise mise au point, oubli de refroidissement de la caméra, etc.) et à pondérer les images retenues. Dans l’idéal, vous arriverez donc à cette dernière étape en ayant préservé la totalité des vos brutes de départ, ce qui vous garantira le meilleur rapport signal sur bruit possible en fonction du nombre d’images unitaires réalisées.
Pour les paramètres d’intégration, ceux-ci diffèrent selon que vous avez suivi la Piste Blanche, Bleue ou Rouge au cours de ce tutoriel.
Pour les paramètres de réjection, ceux-ci ne dépendent moins du parcours suivi que des images réalisées ; même s’il existe quelques subtilités…
Ces deux aspects sont donc traitées séparément ci-après.
Paramètres d’intégration
Selon que vous avez suivi la Piste Blanche, Bleue ou Rouge précédemment, vous pouvez suivre les réglages recommandés ci-dessous, adaptés à chaque parcours :
- la Piste Blanche propose les réglages de base ;
- la Piste Bleue ajoute les options « Drizzle » et « Pondération des images » ;
- la Piste Rouge propose, outre les options de la Piste Bleue, l’option Local Normalization.
Ouvrez le process ImageIntegration, et ajoutez l’ensemble de vos Lights dans « Input Images ».
Sélectionnez dans la liste d’image votre Image Référence-empilement établie précédemment lors de l’étape « sélection des Lights », et cliquez sur « Set Reference ».
Votre image de référence figure désormais en tête de la liste d’images.
Dans l’onglet « Image Integration« , indiquez les réglages suivants :
Combination = Average
Le mode d’intégration par la « moyenne » assure le meilleur rapport signal sur bruit à l’image empilée ; aussi il doit être privilégié aux autres modes dans l’immense majorité des cas.
Ce mode d’intégration offre un rapport signal sur bruit au moins 20% supérieur à la méthode par médiane (et même plus avec un faible nombre d’images…), mais avec une réjection moindre des valeurs déviantes par rapport à l’écart-type de la série.
Toutefois, cela n’est pas un problème dans la mesure où le process ImageIntegration propose par ailleurs des outils complémentaires de réjection avancés. Il n’est pas nécessaire de sacrifier à l’amélioration du rapport signal sur bruit sur ce point…
Normalization = Additive with scaling
Dans la mesure où aucune opération de « normalisation » n’a été réalisée en amont (si vous ne vous êtres pas écartés de la Piste Blanche), le paramètre par défaut « additive » donnera les meilleurs résultats ; inutile de modifier ce paramètre.
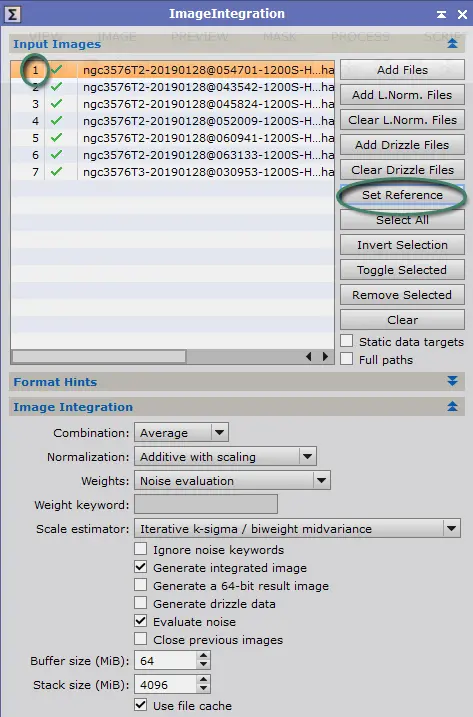
Weights = Noise evaluation
Pour la pondération des images lors de l’empilement, le choix « Noise evaluation » est le plus adapté, dans la mesure où le but de ce process est précisément l’optimisation du rapport signal sur bruit de l’image empilée. Par ailleurs, ce choix est en accord avec notre Image Référence-empilement que nous avons déterminée précédemment en fonction du paramètre SNRWeight.
A noter cependant que si vos images comportent encore à ce stade de forts gradients, cette pondération risque d’être faussée… L’algorithme utilisé par Pixinsight est prévu pour tenir compte de forts gradients dans l’évaluation du SNR, mais la précision de mesure s’en trouvera malgré tout affectée.
Cochez enfin les options « Generate integrated image » et « Evaluate Noise » (obligatoire pour que le process puisse réaliser la pondération sur la base de Noise evaluation !).
Une fois ces options sélectionnées, vous pouvez passer à la phase de « Paramétrage de réjection » ci-après.
Ouvrez le process ImageIntegration, et ajoutez l’ensemble de vos Lights dans « Input Images ».
Pour pouvoir réaliser une image Drizzle par la suite, cliquez sur « Add Drizzle Files » et entrez l’ensemble des fichiers drizzle associés à vos images. Vous devez ajouter un fichier drizzle (.xdrz) pour chacune des images. Si certains fichiers drizzle sont manquants, un message d’information vous signalera cet oubli. Dans la fenêtre « Input Images », chaque image associée à un fichier drizzle est désormais signalée par le symbole « <d> ».
Cochez en plus l’option « Generate drizzle data » afin d’actualiser les fichiers drizzle (.xdrz) lors de cette étape. Notez qu’à cette étape, encore une fois, aucune image drizzle ne sera générée : seuls les fichiers .xdrz vont être actualisés.
Dans l’onglet « Image Integration« , indiquez les réglages suivants :
Combination = Average
Le mode d’intégration par la « moyenne » assure le meilleur rapport signal sur bruit à l’image empilée ; aussi il doit être privilégié aux autres modes dans l’immense majorité des cas.
Ce mode d’intégration offre un rapport signal sur bruit au moins 20% supérieur à la méthode par médiane (et même plus avec un faible nombre d’images…), mais avec une réjection moindre des valeurs déviantes par rapport à l’écart-type de la série.
Toutefois, cela n’est pas un problème dans la mesure où le process ImageIntegration propose par ailleurs des outils complémentaires de réjection avancés. Il n’est pas nécessaire de sacrifier à l’amélioration du rapport signal sur bruit sur ce point…
Normalization = Additive with scaling
Dans la mesure où aucune opération de « normalisation » n’a été réalisée en amont (si vous ne vous êtres pas écartés de la Piste Bleue), le paramètre par défaut « additive » donnera les meilleurs résultats ; inutile de modifier ce paramètre.
Weights =Fits keyword (COEF)
Plutôt que de pondérer chaque image par une estimation de son rapport signal sur bruit à ce stade, nous allons utiliser les coefficients de pondération précédemment calculés.
Le paramètre « Weight Keyword » doit donc être réglé sur « COEF » (ou le mot-clé que vous avez utilisé lors de l’étape de pondération).
Enfin, cochez l’option « Generate integrated image ». Il n’est pas nécessaire de cocher ici l’option « Evaluate noise » puisque le coefficient de pondération va primer sur un éventuel calcul du bruit qui serait effectué lors du process.
Une fois ces options sélectionnées, vous pouvez passer à la phase de « Paramétrage de réjection » ci-après.
Ouvrez le process ImageIntegration, et ajoutez l’ensemble de vos Lights dans « Input Images ».
Pour pouvoir réaliser une image Drizzle par la suite, cliquez sur « Add Drizzle Files » et entrez l’ensemble des fichiers drizzle associés à vos images. Vous devez ajouter un fichier drizzle (.xdrz) pour chacune des images. Si certains fichiers drizzle sont manquants, un message d’information vous signalera cet oubli. Dans la fenêtre « Input Images », chaque image associée à un fichier drizzle est désormais signalée par le symbole « <d> ».
Cochez en plus l’option « Generate drizzle data » afin d’actualiser les fichiers drizzle (.xdrz) lors de cette étape. Notez qu’à cette étape, encore une fois, aucune image drizzle ne sera générée ; les fichiers .xdrz étant seulement actualisés.
Pour intégrer les données générées lors du process Local Normalization, cliquez sur « Add L.Norm. Files » et ajoutez l’ensemble des fichiers LN (.xnml) précédemment générés. Chaque image doit être associée au fichier LN correspondant, matérialisé dans la fenêtre par le symbole « <n> ».
Dans l’onglet « Image Integration« , indiquez les réglages suivants :
Combination = Average
Le mode d’intégration par la « moyenne » assure le meilleur rapport signal sur bruit à l’image empilée ; aussi il doit être privilégié aux autres modes dans l’immense majorité des cas.
Image Integration – Configuration « Piste Rouge ».
Ce mode d’intégration offre un rapport signal sur bruit au moins 20% supérieur à la méthode par médiane (et même plus avec un faible nombre d’images…), mais avec une réjection moindre des valeurs déviantes par rapport à l’écart-type de la série.
Toutefois, cela n’est pas un problème dans la mesure où le process ImageIntegration propose par ailleurs des outils complémentaires de réjection avancés. Il n’est pas nécessaire de sacrifier à l’amélioration du rapport signal sur bruit sur ce point…
Normalization = Local normalization
Dans la mesure où nous avons déjà procédé à la normalisation des images avec le process Local Normalization, il est nécessaire d’utiliser ici les paramètres créés avec ce process et associés à chaque image (avec les fichiers .xnml).
Weights =Fits keyword (COEF)
Plutôt que de pondérer chaque image par une estimation de son rapport signal sur bruit à ce stade, nous allons utiliser les coefficients de pondération précédemment calculés.
Le paramètre « Weight Keyword » doit donc être réglé sur « COEF » (ou le mot-clé que vous avez utilisé lors de l’étape de pondération).
Enfin, cochez l’option « Generate integrated image ». Il n’est pas nécessaire de cocher ici l’option « Evaluate noise » puisque le coefficient de pondération va primer sur un éventuel calcul du bruit qui serait effectué lors du process.
Une fois ces options sélectionnées, vous pouvez passer à la phase de « Paramétrage de réjection » ci-après.
Paramètres de réjection
Contrairement aux paramètres d’intégration, qui dépendent essentiellement des process effectués sur les images avant l’empilement, les paramètres de réjection doivent être adaptés en fonction des images réalisées, et notamment du nombre d’images.
L’algorithme de réjection de pixels « Rejection Algorithm » doit être configuré en fonction du nombre n d’images à empiler. On présente le plus souvent le choix de l’algorithme sous la forme suivante :
- n < 10 : Average sigma clipping ;
- 10 < n < 25 : Winsorized sigma clipping ;
- n > 25 : Linear fit clipping.
Dans le cadre de ce tutoriel, nous nous limiterons à ce choix sans le justifier davantage. Retenons simplement qu’il serait plus correct de dire, par exemple, que la méthode de réjection Linear Fit clipping ne donne de bons résultats qu’à partir de 25 images… Nous traiterons plus en détail des différents algorithmes de réjection proposés par Pixinsight dans un article détaillé.
Activez les options « Clip low/high pixels » mais décochez « Clip low/high range ».
Enfin, réglez la valeur des sigma (ou Linear Fit le cas échéant) low et high, à des valeurs suffisamment hautes pour autoriser les réjections des seules valeurs réellement marginales.
Ces valeurs dépendront essentiellement de la qualité du ciel et de vos images (refroidissement du capteur…) ainsi que du nombre d’images à empiler.
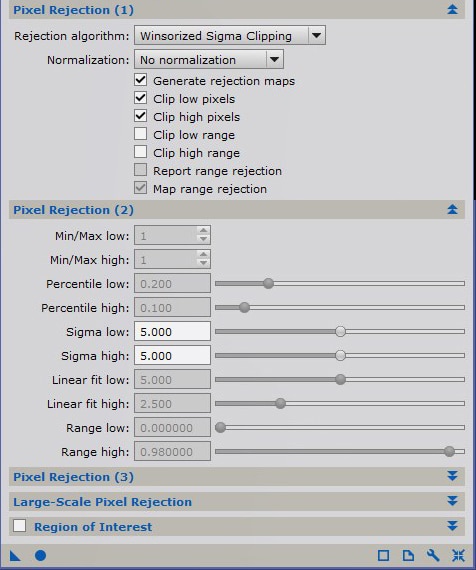
Personnellement, j’utilise une règle simple pour fixer les sigmas low et high de départ : la racine carrée du nombre d’images à empiler, avec un minimum de 3 et un maximum de 6 :
- n < 16 : sigma = 3
- 16 < n < 25 : sigma = 4
- 25 < n < 36 : sigma = 5
- n > 36 : sigma = 6
Il ne s’agit bien sûr ici que des valeurs de départ pour un premier essai, qu’il convient ensuite d’affiner avec plusieurs essais…
Lancez le process et vérifiez les résultats obtenus sur l’image d’empilement, ainsi que sur les images de réjection low et high (avec la fonction STF bien sûr).
L’image de réjection « low » doit contenir un nombre limité de pixels épars : si de grandes zones sont affectées, c’est que les paramètres de réjection low sont trop bas : augmentez alors la valeur de sigma low.
L’image de réjection « high » peut contenir un nombre plus important de pixels, et il convient notamment de vérifier que sont bien prises en compte les traînées de satellites qui doivent normalement être totalement supprimées lors de l’empilement.
Si des traînées de satellite demeurent visibles, la valeur de sigma high doit être diminuée afin que la réjection soit plus restrictive. La réjection des traînées ne doit cependant pas entraîner celle d’un trop grand nombre de pixels, en particulier de pixels adjacents regroupés dans une zone de forte luminosité de l’image : c’est le signe que la réjection est trop forte et que des valeurs pertinentes commencent à être rejetées…
Une solution alternative pour supprimer les traînées tenaces sur les images, mais plus délicate à bien paramétrer, est de ne pas trop abaisser les valeurs de sigma high et d’utiliser l’option complémentaire Large-Scale Pixel Rejection expliquée en « Piste Bleue » ci-après.
Dans tous les cas, ne diminuez pas les valeurs de sigma low et high trop bas. Des valeurs inférieures à 3 sont déjà à éviter ; en dessous de 2 cela devient très critique…
Affinez bien sûr séparément les valeurs low et high si besoin.
En complément des paramètres de la Piste Blanche, voici une nouvelle option intéressante apportée par la version 1.8.5 de Pixinsight, très utile si vous avez des traînées de satellite tenaces sur vos images.
L’option Large-Scale Pixel Rejection permet en effet une élimination ciblée des défauts affectant les larges structures : les valeurs déviantes sont estimées non plus pixel par pixel, mais par layers (niveau de structures).
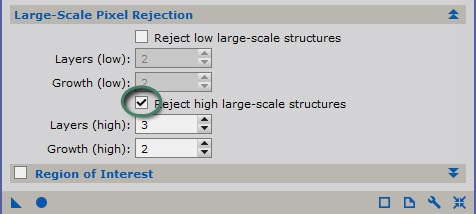
Dans ce cas précis, seule l’option « Reject high large-scale structures » peut être activée, en jouant sur la valeur de « Layers (high) » qui doit être ajusté en fonction de la largeur des traînées résiduelles.
L’avantage de cette fonction est de pouvoir traiter les traînées tenaces sans pour autant abaisser outre mesure les fonctions de sigma, donc sans sacrifier les seuils de réjection adaptés à l’ensemble de l’image, abstraction faite de ces défauts.
Lorsque vous êtes satisfait des résultats obtenus, sauvegardez précieusement l’image ainsi obtenue.
Si vous suivez la Piste Blanche, bravo : le prétraitement de votre image est terminé ! 🙂
A titre personnel, je vous recommande toutefois vivement de poursuivre encore un peu et de générer une image en mode Drizzle !
11. Génération d’une image Light drizzle
Pourquoi générer une image en mode Drizzle ?
Générer une image « drizzle » permet d’augmenter la taille d’une image d’un facteur déterminé (généralement 2) de manière bien plus précise qu’une simple augmentation de la taille de l’image à 200%.
Pour être efficace, le drizzle doit être envisagé dès l’acquisition des images car sa mise en oeuvre suppose de disposer d’un nombre d’images important, et que les images soient décalées de quelques pixels entre elles (le décalage lié au dithering permet de réaliser simplement cette condition).
La génération d’une image en mode « drizzle » présente beaucoup d’avantages, avec une finesse d’image améliorée et des étoiles qui ressortent plus rondes et moins « pixelisées » (pour les plus petites). Attention cependant, pas de miracles à attendre : le drizzle n’augmente pas la résolution réelle de l’image !
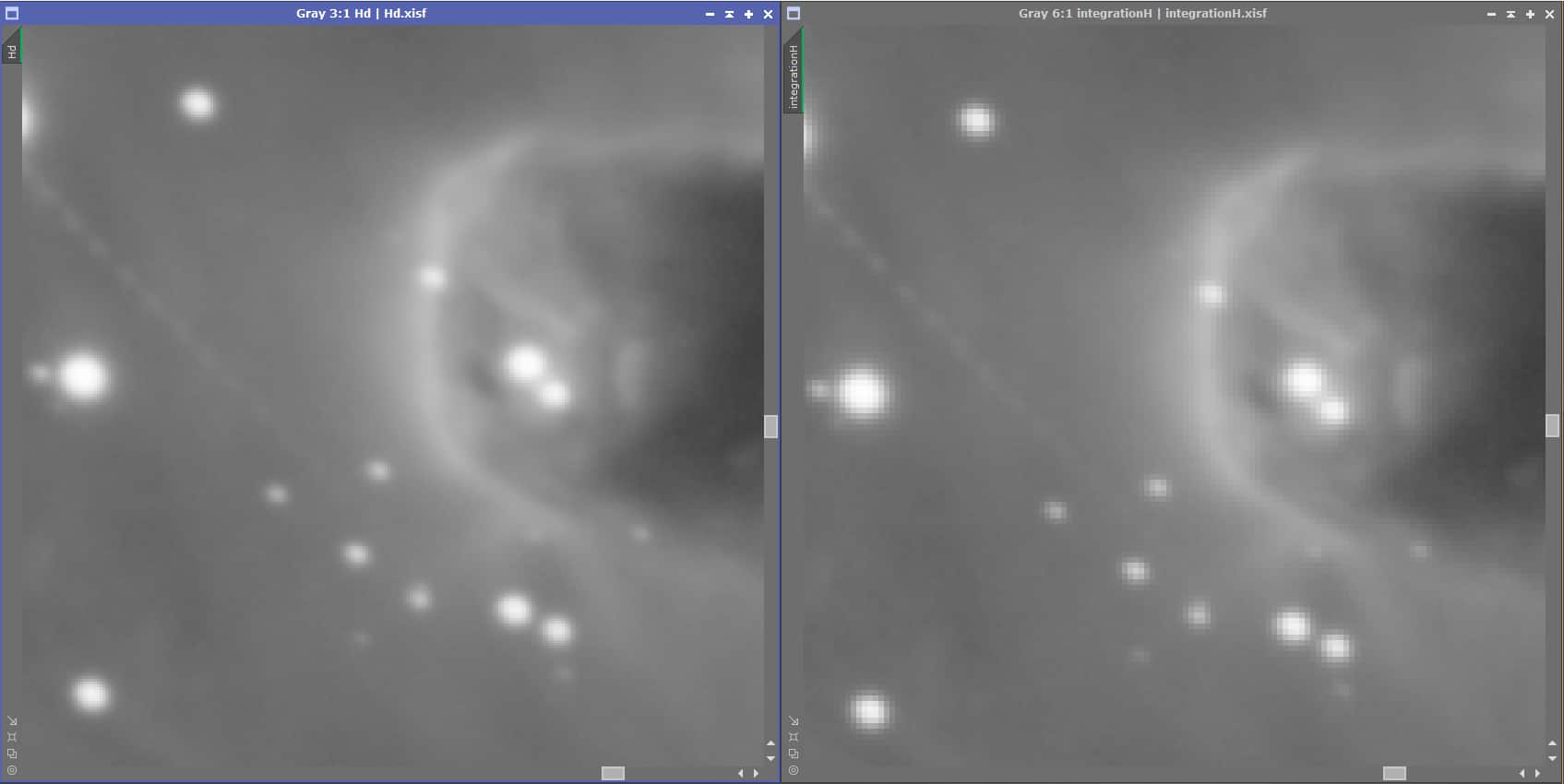
La plus grande taille de l’image, associée à une meilleure finesse, facilite la mise en oeuvre de certains process lors du traitement ; ce qui est un avantage important. Pour ma part, sauf à de très rares exceptions, je ne traite plus mes images qu’en mode drizzle.
Mais un avantage énorme du drizzle est de pouvoir « récupérer », de manière parfois spectaculaire, certaines bandes noires en bord de champ générées par l’empilement et liées au décalage des images Light : alors que ces bandes devraient être cropées sur l’image normale, l’image drizzle permet de limiter au maximum ce crop !
Voici un exemple d’une telle « récupération » des bandes noires issues de l’empilement :
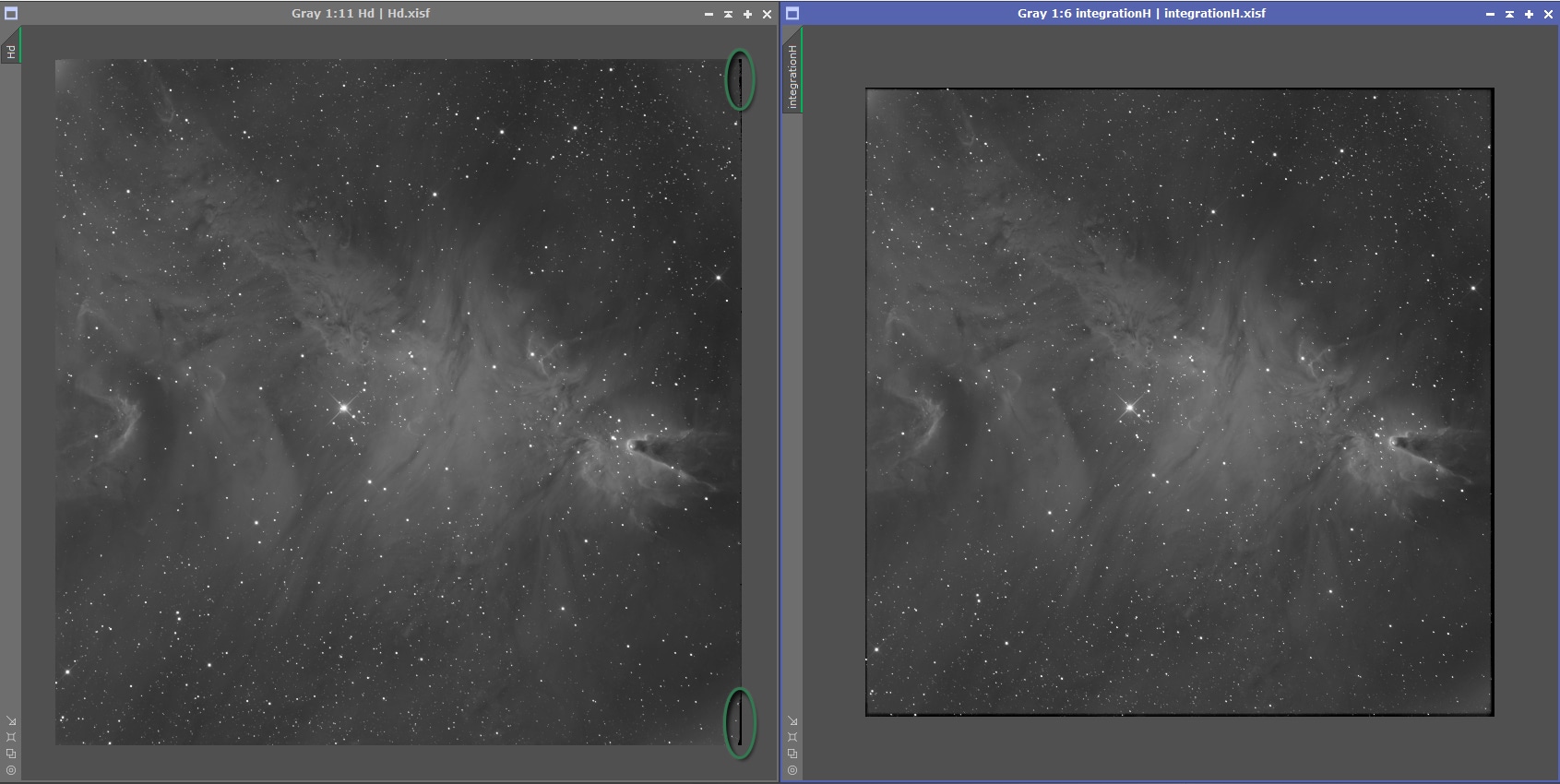
Naturellement, le rapport signal sur bruit dans ces zones est moindre que sur le reste de l’image, mais il est souvent préférable de conserver ces zones.

L’inconvénient du drizzle est une légère augmentation du bruit, et surtout un ralentissement des process de traitement ultérieurs puisque pour un drizzle 2x, le volume d’information est quadruplé…
Notez que vous pouvez également générer une image drizzle puis redimensionner immédiatement votre image pour lui rendre sa taille initiale, en continuant de bénéficier des avantages obtenus avec le drizzle.
Paramétrage
Au cours des précédentes étapes, la prise en compte du drizzle n’a encore généré aucune image, mais a seulement permis de créer et d’actualiser des fichiers .xdrz. Il est enfin temps de générer cette image sur la base de ces fichiers !
La mise en oeuvre du process Drizzle est très simple : lancez le process, ajoutez les fichiers .xdrz dans leur dernière version et sélectionnez le taux d’agrandissement « Scale ».
Le facteur « Scale » par défaut est de 2 ; ce qui convient parfaitement pour les images réalisées en bin1.
Si vous avez réalisé l’image de luminance en bin1 et les images RGB en bin2 et que vous souhaitez générer des images drizzle de même taille, il conviendra de retenir « Scale = 2 » pour la luminance et « Scale = 4 » pour les images RGB.
Lancez le process, vérifier que l’image générée ne contient pas d’artefacts issus du passage en drizzle et sauvegardez l’image si celle-ci vous convient.
Nous voici parvenus au terme de la Piste Bleue : félicitations, le prétraitement de votre image est terminé ! 🙂
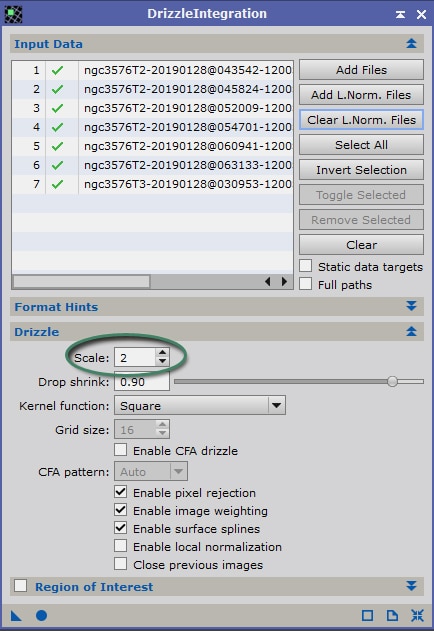
Si vous avez procédé à l’étape Local Normalization, le paramétrage du process Drizzle est identique à celui expliqué en Piste Bleue ci-dessus, à une petite subtilité près.
Vous pouvez désormais intégrer les données de Local Normalization lors de la génération drizzle, afin de bénéficier des améliorations apportées par cette normalisation.
Cliquez sur « Add L.Norm. Files » et ajoutez l’ensemble des fichiers LN (.xnml) précédemment générés. Chaque fichier drizzle .xdrz est ainsi associé au fichier LN correspondant, matérialisé dans la fenêtre par le symbole « <n> ».
Procédez aux autres réglages et lancez le process.
Vérifiez que l’image obtenue est dépourvue d’artefacts et sauvegardez l’image drizzle obtenue.
Félicitations ! Le prétraitement en mode « Piste Rouge » est terminé ! 🙂
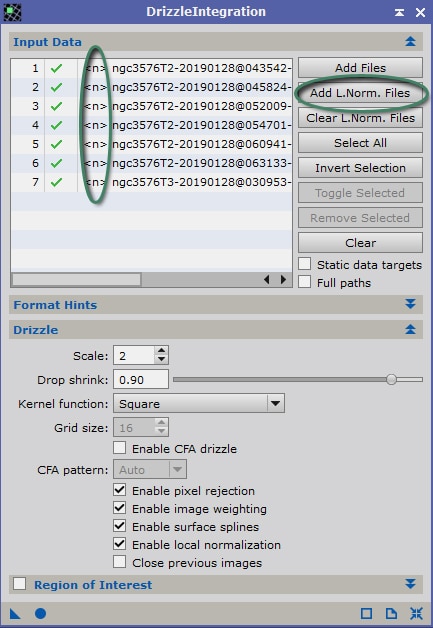
CONCLUSION…
Nous voici parvenus au terme du processus de prétraitement…
J’espère que ce (long) tutoriel vous aura été utile et que vous y aurez trouvé des astuces intéressantes qui vous auront aidé à progresser.
Peut-être même qu’une meilleure connaissance des enjeux des différentes étapes du prétraitement vous aura donné envie – comme moi – d’approfondir plus encore cette étape trop souvent mise de côté. Soyez assurés que le traitement ultérieur de votre image vous procurera encore plus de plaisir.
Ce tutoriel sera actualisé en fonction des évolutions de Pixinsight et de mes propres modifications de process… n’hésitez pas à poster un commentaire si certains points méritent selon vous plus d’explications, que certaines choses ne sont pas claires ou encore pour toute question… j’essaierai d’en tenir compte pour les prochaines mises à jour !



Tutoriel de sauvetage pour une lunette inondée
Votre lunette astronomique a pris l’eau ? Découvrez dans ce tutoriel comment sauver votre optique après une infiltration d’eau entre les lentilles. Ce guide pratique, basé sur une expérience réelle, vous explique pas à pas comment sécher l’instrument, éliminer la condensation et prévenir l’apparition de champignons grâce à un traitement UV. Apprenez les gestes qui sauvent pour éviter des dommages irréversibles à votre précieux matériel !

Améliorer les détails d’une image avec Photoshop
Plusieurs méthodes pour améliorer les détails d’une image avec Photoshop, tant dans les zones lumineuses que dans les zones sombres, avec la création de masques adaptés.

Améliorer les détails d’une image avec Pixinsight
Plusieurs méthodes pour améliorer les détails d’une image avec Pixinsight, tant dans les zones lumineuses que dans les zones sombres, avec la création de masques adaptés.